华为昇腾服务器配置大模型及微调涉及多个步骤,包括环境搭建、模型转换、模型部署和微调等。以下是一个简要的指南,帮助你完成这些任务。
### 1. 环境搭建
#### 1.1 安装昇腾软件栈
首先,确保你的昇腾服务器已经安装了昇腾软件栈(CANN)。你可以从华为官网下载并安装适合你服务器的版本。
```bash
# 下载CANN安装包
wget https://cann.huawei.com/cann-installer/latest/HCC-
# 安装CANN
sudo ./HCC-
#### 1.2 安装依赖库
安装必要的依赖库,如PyTorch、TensorFlow等。
```bash
# 安装PyTorch
pip install torch torchvision
# 安装TensorFlow
pip install tensorflow
```
### 2. 模型转换
#### 2.1 转换为昇腾格式
使用昇腾提供的模型转换工具将你的大模型转换为昇腾格式。
```bash
# 转换PyTorch模型
torchscript_model = torch.jit.trace(your_model, torch.rand(1, 3, 224, 224))
torchscript_model.save("model.pt")
# 使用ATC工具
相关内容:
| 整个六月份全耗在这个上面了,吐血整理,且看且珍惜!!! |
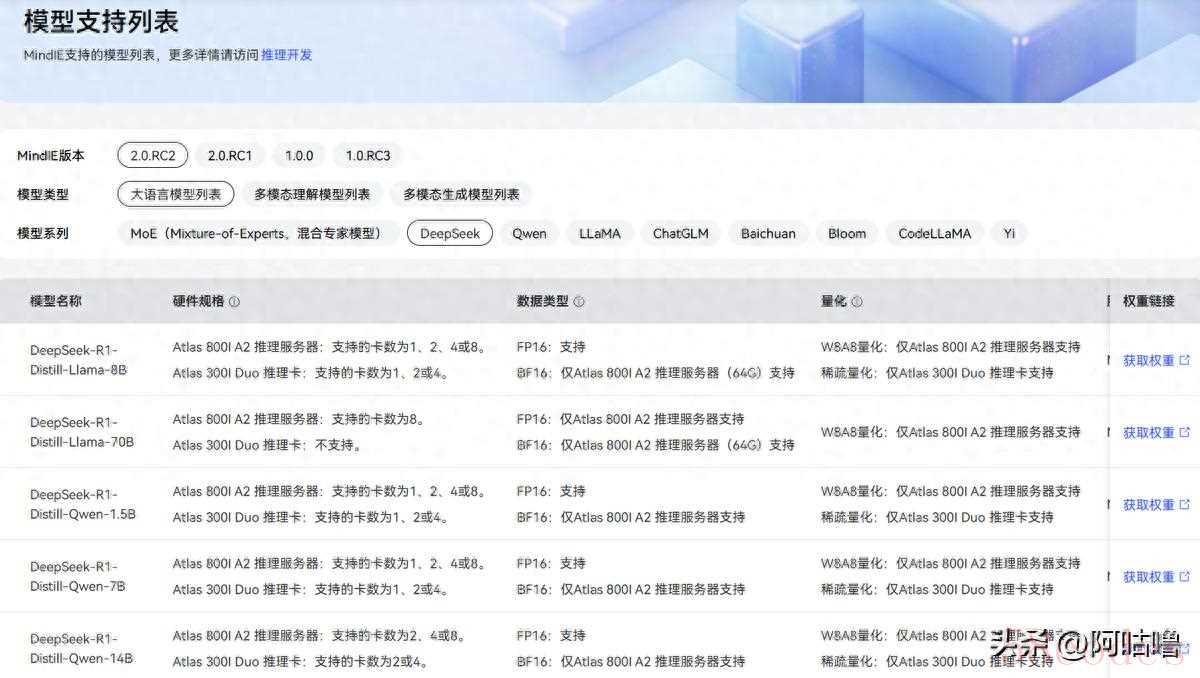 3、MindIE文本生成推理快速入门(https://www.hiascend.com/document/detail/zh/mindie/20RC2/quickstart/mindie-trip-0002.html),这个文档可以帮助我们快速部署模型,我们部署中遇到的大多数问题可以在这里找到答案。
3、MindIE文本生成推理快速入门(https://www.hiascend.com/document/detail/zh/mindie/20RC2/quickstart/mindie-trip-0002.html),这个文档可以帮助我们快速部署模型,我们部署中遇到的大多数问题可以在这里找到答案。 二、操作步骤由于官方提供的容器里面初始化好了MindIE,我们就不用再操心MindIE的安装了,感兴趣的朋友可以查看这个安装指南(https://www.hiascend.com/document/detail/zh/mindie/20RC2/envdeployment/instg/mindie_instg_0001.html)。1、模型准备我是根据模型支持列表里面选择的是适配我的硬件的模型,执行以下命令查看NPU
二、操作步骤由于官方提供的容器里面初始化好了MindIE,我们就不用再操心MindIE的安装了,感兴趣的朋友可以查看这个安装指南(https://www.hiascend.com/document/detail/zh/mindie/20RC2/envdeployment/instg/mindie_instg_0001.html)。1、模型准备我是根据模型支持列表里面选择的是适配我的硬件的模型,执行以下命令查看NPU| Plaintext npu-smi info |
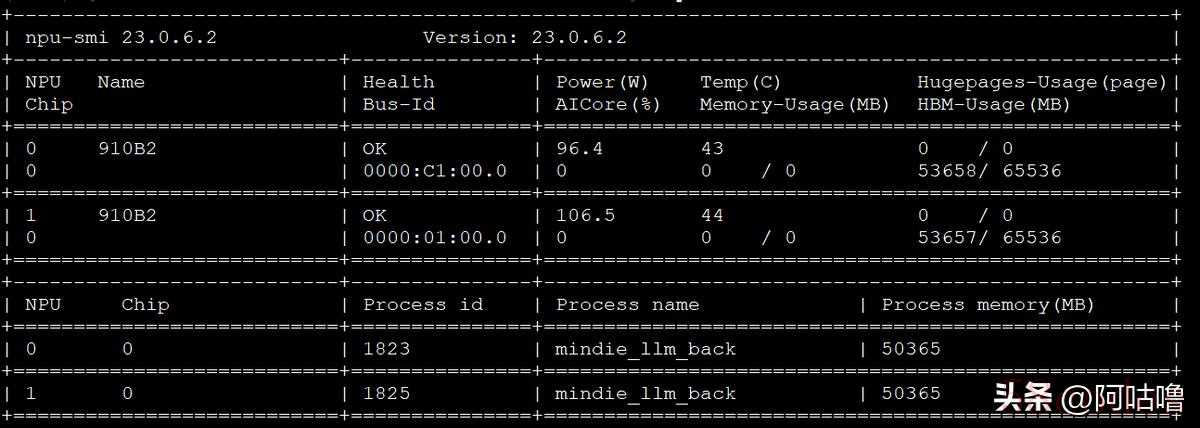 我根据我的配置选择的是DeepSeek-R1-Distill-Qwen-32B,可以从魔塔社区下载该模型,https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B/,下载好后将其上传到/data目录下2、环境配置容器默认安装MindeIE的路径是/usr/local/Ascend,所以我们只需要在默认路径下修改配置文件即可,不用做其他环境变量的配置;
我根据我的配置选择的是DeepSeek-R1-Distill-Qwen-32B,可以从魔塔社区下载该模型,https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B/,下载好后将其上传到/data目录下2、环境配置容器默认安装MindeIE的路径是/usr/local/Ascend,所以我们只需要在默认路径下修改配置文件即可,不用做其他环境变量的配置;| Bash source /usr/local/Ascend/ascend-toolkit/set_env.sh source /usr/local/Ascend/nnal/atb/set_env.sh source /usr/local/Ascend/mindie/set_env.sh source /usr/local/Ascend/atb-models/set_env.sh |
| JSON { "Version": "1.0.0", "ServerConfig": { "ipAddress": "127.0.0.1", "managementIpAddress": "127.0.0.2", "port": 1025, "managementPort": 1026, "metricsPort": 1027, "allowAllZeroIpListening": false, "maxLinkNum": 1000, "httpsEnabled": false, // 若未完成TLS配置,先关闭HTTPS "fullTextEnabled": false, "tlsCaPath": "", // 清理无效路径 "tlsCaFile": , // 清理无效文件 "tlsCert": "", // 清理无效文件 "tlsPk": "", // 清理无效文件 "tlsPkPwd": "", // 清理无效文件 "tlsCrlPath": "", // 清理无效路径 "tlsCrlFiles": , // 清理无效文件 "managementTlsCaFile": , // 清理无效文件 "managementTlsCert": "", // 清理无效文件 "managementTlsPk": "", // 清理无效文件 "managementTlsPkPwd": "", // 清理无效文件 "managementTlsCrlPath": "", // 清理无效路径 "managementTlsCrlFiles": ,// 清理无效文件 "kmcKsfMaster": "", // 清理无效路径 "kmcKsfStandby": "", // 清理无效路径 "inferMode": "standard", "interCommTLSEnabled": false, // 关闭多节点TLS(单机部署) "interCommPort": 1121, "openAiSupport": "vllm", "tokenTimeout": 600, "e2eTimeout": 600, "distDPServerEnabled": false }, "BackendConfig": { "backendName": "mindieservice_llm_engine", "modelInstanceNumber": 1, "npuDeviceIds": ], // 双卡配置 "tokenizerProcessNumber": 8, "multiNodesInferEnabled": false, "interNodeTLSEnabled": false, // 关闭多节点TLS "ModelDeployConfig": { "maxSeqLen": 2560, "maxInputTokenLen": 2048, "truncation": false, "ModelConfig": }, "ScheduleConfig": { "templateType": "Standard", "templateName": "Standard_LLM", "cacheBlockSize": 128, "maxPrefillBatchSize": 128, "maxPrefillTokens": 8192, "prefillTimeMsPerReq": 150, "prefillPolicyType": 0, "decodeTimeMsPerReq": 50, "decodePolicyType": 0, "maxBatchSize": 200, "maxIterTimes": 512, "maxPreemptCount": 0, "supportSelectBatch": false, "maxQueueDelayMicroseconds": 5000 } } } |
| Bash chmod -R 750 /data/DeepSeek-R1-Distill-Qwen-32B |
| Bash cd /usr/local/Ascend/mindie/latest/mindie-service/ nohup ./bin/mindieservice_daemon > output.log 2>&1 & # 日志中输出Daemon start success!则表示服务启动成功 |
| JSON curl -X POST http://127.0.0.1:7860/v1/chat/completions -H "Content-Type: application/json" -d '{ "model": "DeepSeek-R1-Distill-Qwen-32B", "messages": }' |
| Plaintext ps -ef | grep mindieservice |
| JSON kill -9 主进程ID # 或者 pkill -9 mindieservice |
| JSON # 设置华为源 pip config set global.index-url https://mirrors.huaweicloud.com/repository/pypi/simple pip config set global.trusted-host mirrors.huaweicloud.com conda deactivate conda install mindspore=2.6.0 -c mindspore -c conda-forge python -c "import mindspore;mindspore.set_device('Ascend');mindspore.run_check()" yum install hostname -y |
| Bash # 数据转换 python research/qwen2/alpaca_converter.py --data_path /data/datasets/alpaca-data.json --output_path /data/datasets/alpaca-data-messages.json # 数据预处理和Mindrecord数据生成 python research/qwen2/qwen2_preprocess.py --dataset_type 'qa' --input_glob /data/datasets/alpaca-data-all.json --vocab_file /data/Qwen2-0.5B/vocab.json --merges_file /data/Qwen2-0.5B/merges.txt --seq_length 4096 --output_file /data/datasets/alpaca-all.mindrecord python research/qwen2/qwen2_preprocess.py --dataset_type 'qa' --input_glob /data/s1/alpaca-data-all.json --vocab_file /data/Qwen2.5-0.5B-Instruct/vocab.json --merges_file /data/Qwen2.5-0.5B-Instruct/merges.txt --seq_length 4096 --output_file /data/datasets/alpaca-all-qwen25.mindrecord |
| JSON # 权重转换 python convert_weight.py --model qwen2 --input_path /data/Qwen2-0.5B/ --output_path /data/ckpt/qwen2_0_5b.ckpt --dtype bf16 # 参数说明 model: 模型名称 input_path: 下载HuggingFace权重的文件夹路径 output_path: 转换后的MindSpore权重文件保存路径 dtype: 转换权重的精度 is_lora: 转换的权重是否是lora align_rank: lora配置中rank的值是否对齐 # Qwen2.5系列默认打开qkv_concat参数,使用的权重需经过qkv_concat转换 python research/qwen2_5/convert_weight.py --pre_ckpt_path /data/Qwen2.5-7B/ --mindspore_ckpt_path /data/qkv/qwen2.5_7b_ms.ckpt --qkv_concat True --config_path /data/Qwen2.5-7B/mindformers_config.json |
| Plaintext # 参数说明 qkv_concat: 是否开启qkv_concat,默认为false pre_ckpt_path: 转化后的MindSpore权重文件保存路径,单卡权重指向文件,多卡权重指向文件夹 mindspore_ckpt_path: qkv_concat转换后权重文件保存路径,单卡权重指向文件,多卡权重指向文件夹 python -c "import mindspore as ms; print(ms.load_checkpoint('/data/ckpt/qwen2_5_7b.ckpt').keys())" | head # 可能会缺torch pip install torch==2.1.0 |
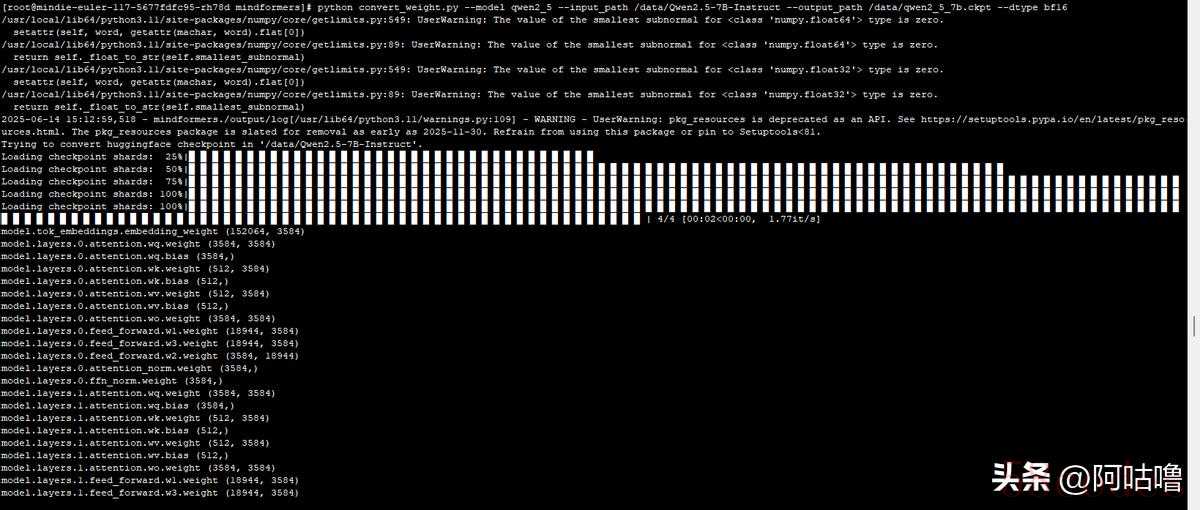
 4、开始微调
4、开始微调| JSON # 微调7B,内存不够,失败 bash scripts/msrun_launcher.sh "run_mindformer.py --register_path research/qwen2_5 --config /data/config/qwen7b.yaml --train_dataset_dir /data/datasets/alpaca-messages-qwen7b.mindrecord --run_mode finetune" 2 # 微调qwen2.5-0.5B Safetensors权重成功 bash scripts/msrun_launcher.sh "run_mindformer.py --register_path research/qwen2_5 --config /data/config/qwen2.yaml --train_dataset_dir /data/datasets/alpaca-all-qwen25.mindrecord --run_mode finetune" 2 # 微调qwen2-0.5B,ckpt权重成功 bash scripts/msrun_launcher.sh "run_mindformer.py --config /data/config/qwen.yaml --load_checkpoint /data/ckpt/qwen2_0_5b.ckpt --train_dataset_dir /data/datasets/Qwen2-0.5B/alpaca-messages.mindrecord --run_mode finetune" 2 # 微调qwen2 0.5B Safetensors权重成功 bash scripts/msrun_launcher.sh "run_mindformer.py --register_path research/qwen2 --config /data/config/qwen.yaml --train_data /data/datasets/Qwen2-0.5B/alpaca-messages.mindrecord --run_mode finetune" 2 |
| YAML # 参数说明 config: 模型的配置文件,文件在MindSpore Transformers代码仓中config目录下 load_checkpoint: checkpoint文件的路径 train_dataset_dir: 训练数据集路径 use_parallel: 是否开启并行 run_mode: 运行模式,train:训练,finetune:微调,predict:推理 load_checkpoint: './path/Qwen2_5_0.5b' # HuggingFace下载的safetensors权重文件目录 load_ckpt_format: 'safetensors' # 指定加载的权重文件格式为safetensors auto_trans_ckpt: True # 加载完整权重时需打开此配置项,开启在线切分功能 train_dataset: &train_dataset data_loader: type: MindDataset dataset_dir: "./path/alpaca-data.mindrecord" # 实际微调数据集 shuffle: True # runner config runner_config: epochs: 1 # 刚开始微调建议改成1,这个表示训练测次数 batch_size: 1 sink_mode: True sink_size: 1 gradient_accumulation_steps: 8 # parallel config parallel_config: data_parallel: 1 model_parallel: 2 pipeline_stage: 1 use_seq_parallel: True micro_batch_num: 1 vocab_emb_dp: False gradient_aggregation_group: 4 micro_batch_interleave_num: 2 # processor config processor: return_tensors: ms tokenizer: model_max_length: 32768 vocab_file: "./path/vocab.json" # 参考qwen2_5-7b官网下载的词表 merges_file: "./path/merges.txt" # # 参考qwen2_5-7b官网下载的merge文件 #callbacks config callbacks: - type: CheckpointMonitor checkpoint_format: safetensors # 指定微调后保存的权重文件格式为safetensors |
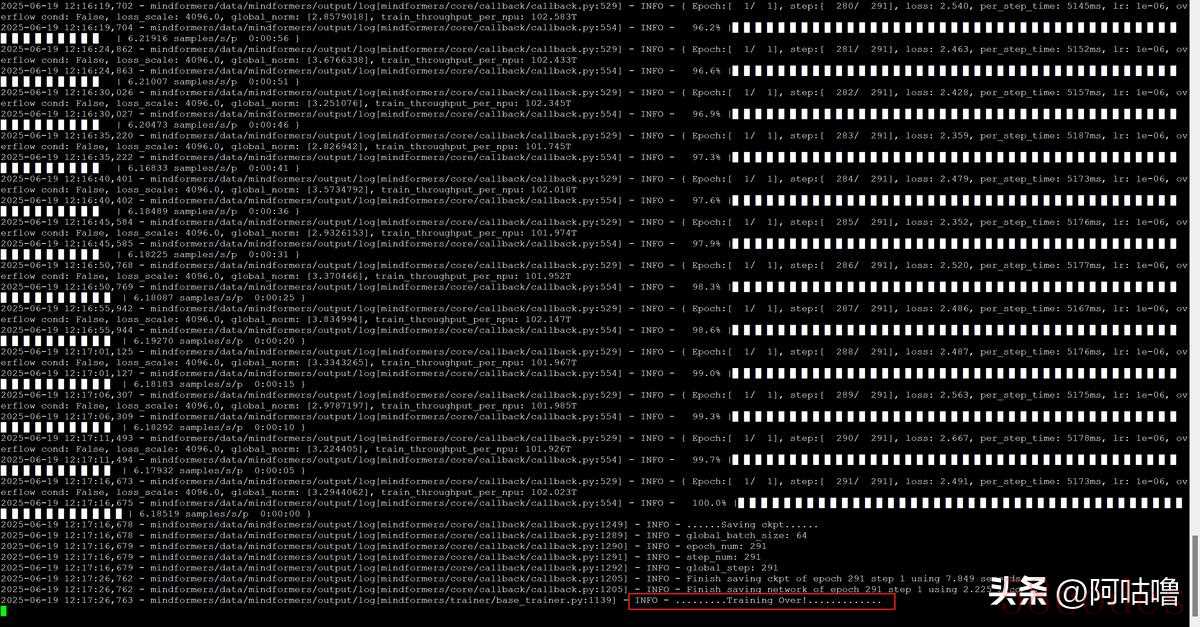 5、推理测试
5、推理测试| JSON # 执行命令 bash scripts/msrun_launcher.sh "run_mindformer.py --register_path research/qwen2 --config /data/config/qwent.yaml --src_strategy_path_or_dir /data/mindformers/strategy_qwen2/ckpt_strategy_rank_0.ckpt --run_mode predict --use_parallel True --auto_trans_ckpt True --predict_data '你是谁'" 2 bash scripts/msrun_launcher.sh "run_mindformer.py --register_path research/qwen2_5 --load_checkpoint /data/mindformers/qw2_output/checkpoint_network --config /data/config/qwent.yaml --src_strategy_path_or_dir /data/mindformers/qw2_output/strategy --run_mode predict --use_parallel True --auto_trans_ckpt True --predict_data /data/datasets/test.txt" 2 |
 四、通过Docker来创建环境1、在公共桶下载镜像,然后执行docker load -i ****
四、通过Docker来创建环境1、在公共桶下载镜像,然后执行docker load -i ****| Bash # 查看宿主机设备情况 ls -l /dev/davinci* /dev/devmm_svm /dev/hisi_hdc docker run -it -d --shm-size=2g --name deepseek --device=/dev/davinci0 --device=/dev/davinci2 --device=/dev/davinci_manager --device=/dev/hisi_hdc --device=/dev/devmm_svm -p 8080:80 -p 7860:7860 -p 8118:8118 -p 9090:90 -v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro -v /usr/local/sbin:/usr/local/sbin:ro -v /root/data:/data mindie:2.0.RC1.B120-800I-A2-py3.11-openeuler24.03-lts-aarch64 bash docker exec -it qwen2 bash |
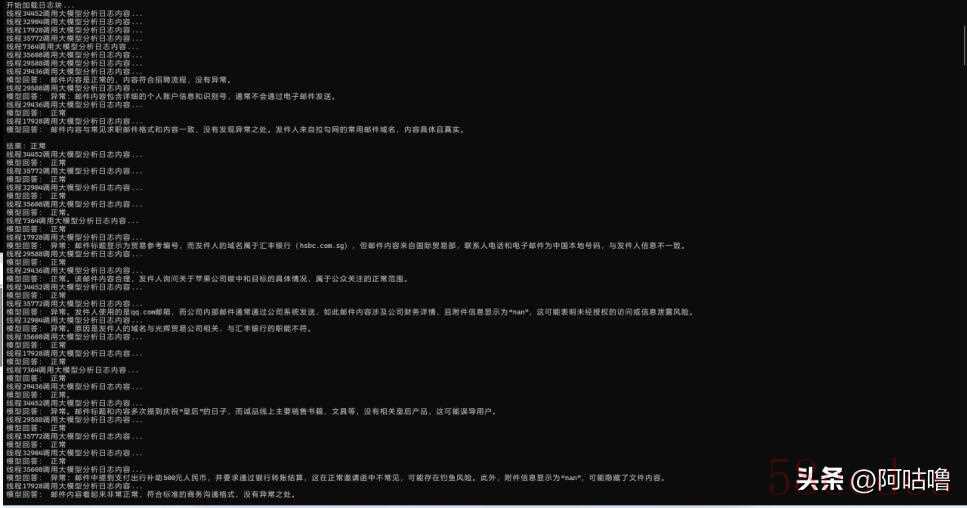
| Python import csv from concurrent.futures import ThreadPoolExecutor, as_completed from openai import OpenAI import pandas as pd # 初始化大模型客户端 client = OpenAI(base_url="http://127.0.0.1:7860/v1", api_key="none") # 输入 Excel 文件路径(邮件日志) log_path = "/data/s1/S1_stage_one_test_data/S1_stage_one_test_data_employee_email_log.xlsx" # 输出结果文件路径 output_csv = "/data/s1/email_result.csv" # 并发线程数 max_workers = 4 def chunk_logs(file_path, chunk_size=100): """将日志按行分块(用于并发处理)""" df = pd.read_excel(file_path, nrows=10) num_rows = len(df) for i in range(0, num_rows, chunk_size): yield df.iloc.to_dict(orient='records') def analyze_log_entry(log): """分析单条日志记录是否异常,返回日志ID和模型分析结果""" print('正在分析日志内容...') try: prompt = ( "请根据以下邮件日志内容判断是否异常,只返回“异常”或“正常”," "如为异常,请简要说明原因: " f"标题:{log.get('subject', '')} " f"发件人域名:{log.get('发件人域名', '')} " f"工号:{log.get('工号', '')} " f"邮件内容:{log.get('context', '')} " f"附件信息:{log.get('attachment', '')} " ) # prompt = ( # "请根据以下EDR日志内容判断是否异常,只返回“异常”或“正常”," # "如为异常,请简要说明原因: " # f"工号:{log.get('工号', '')} " # f"执行命令::{log.get('cmd', '')} " # f",可执行路径:{log.get('file_path', '')} " # ) # prompt = ( # "请根据以下DNS日志内容判断是否异常,只返回“异常”或“正常”," # "如为异常,请简要说明原因: " # f"查询域名:{log.get('req_name', '')} " # ) response = client.chat.completions.create( model="DeepSeek-R1-Distill-Qwen-32B", messages=, temperature=0 ) answer = response.choices.message.content.strip() print("模型:", answer) except Exception as e: answer = f"调用失败: {e}" return { "日志ID": log.get("日志ID", ""), "分析结果": answer } def analyze_log_chunk(chunk): """处理日志块中的每条记录""" results = for log in chunk: result = analyze_log_entry(log) results.append(result) return results def main(): # 加载日志块 chunks = list(chunk_logs(log_path)) results = # 多线程并发分析 with ThreadPoolExecutor(max_workers=max_workers) as executor: futures = for future in as_completed(futures): try: chunk_results = future.result() results.extend(chunk_results) except Exception as e: print(f"处理异常: {e}") # 写入CSV with open(output_csv, mode="w", newline="", encoding="utf-8") as f: writer = csv.DictWriter(f, fieldnames=) writer.writeheader() writer.writerows(results) print(f"✅ 所有日志处理完毕,结果已保存至 {output_csv}") if __name__ == "__main__": main() |
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏
