RDMA(Remote Direct Memory Access)是一种高性能网络技术,它允许网络设备直接访问远程计算机的内存,而无需CPU的参与。这可以显著提高数据传输速度并减少延迟。然而,配置和管理RDMA环境可能会相当复杂,以下是一些基于运维经验的调优建议:
1. "硬件兼容性":确保所有硬件组件(如网络适配器、交换机和服务器)都支持RDMA。不同厂商和型号的设备可能存在兼容性问题。
2. "驱动程序和固件":安装最新版本的RDMA驱动程序和固件。制造商经常发布更新以解决性能问题和兼容性问题。
3. "网络配置":配置网络以支持RDMA。这可能包括启用iWARP或RoCE(RDMA over Converged Ethernet)等RDMA协议,以及配置网络参数,如MTU(最大传输单元)和VLAN(虚拟局域网)。
4. "安全设置":虽然RDMA提供了高性能,但也需要适当的安全措施。确保使用安全协议(如SR-IOV)和配置防火墙规则以保护RDMA通信。
5. "性能监控":使用性能监控工具来跟踪RDMA性能。这可以帮助识别瓶颈和性能问题。
6. "负载均衡":如果可能,使用负载均衡技术来分配RDMA流量,以确保所有服务器和网络设备都得到公平的负载。
7. "故障排除":当遇到问题时,使用
相关内容:
前言:踩坑三年,终于摸透了RDMA这头野兽
说实话,刚接触RDMA的时候我也是一头雾水。什么InfiniBand、RoCE、iWARP,听起来就像天书一样。但是没办法啊,公司上了高性能计算集群,老板说要用RDMA提升网络性能,不然HPC应用跑不起来。
经过三年多的摸爬滚打,踩过无数坑,终于算是把RDMA这套东西搞明白了。今天就把我的一些经验分享出来,希望能帮到正在或者即将接触RDMA的兄弟们。
RDMA到底是个啥?别被那些技术文档唬住了
RDMA(Remote Direct Memory Access)说白了就是让两台机器之间直接访问对方的内存,绕过操作系统内核,减少CPU开销和延迟。听起来很玄乎,但实际上就是为了解决传统TCP/IP网络在高性能计算场景下的瓶颈问题。
我们先看看RDMA的几种实现方式:
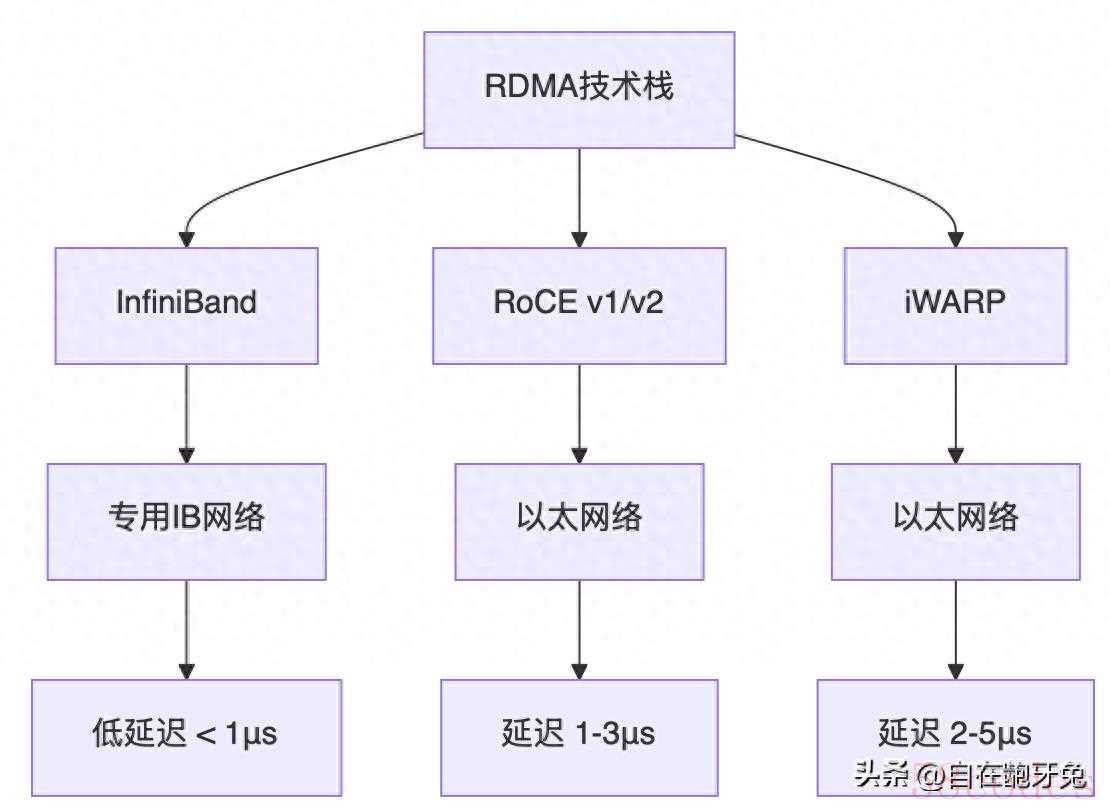
InfiniBand:老大哥,性能最强但成本最高
InfiniBand是RDMA的鼻祖,专用硬件,性能确实没话说。我们之前用的Mellanox ConnectX-5,单口100Gbps,延迟能做到700ns以下。但是!成本真的很高,一个36口的IB交换机要几十万,小公司真心用不起。
RoCE:性价比之王,但坑也不少
RoCE(RDMA over Converged Ethernet)是在以太网上跑RDMA,成本相对低很多。分为RoCE v1和RoCE v2:
- RoCE v1:只能在二层跑,局限性很大
- RoCE v2:支持三层路由,可扩展性更好
我现在主推RoCE v2,配合Mellanox的网卡,性价比确实不错。
iWARP:最没存在感的老三
iWARP基于TCP/IP,兼容性最好,但性能相比前两者就差点意思了。除非你们公司有特殊需求,否则不太建议选这个。
硬件选型:别被销售忽悠了
网卡选择
经过这几年的对比测试,我的建议是:
高端场景:Mellanox ConnectX-6 Dx
- 支持200Gbps
- 硬件卸载功能丰富
- 驱动稳定性好
- 就是贵,一张卡要1-2万
中端场景:Mellanox ConnectX-5
- 100Gbps够用
- 性价比不错
- 市场保有量大,好维护
入门场景:Intel E810系列
- 价格便宜
- 但RDMA功能相对简单
- 适合预算有限的场景
交换机选择
核心交换机:Mellanox Spectrum-3/4系列
- 端口密度高
- 支持SHARP(集合通信加速)
- 适合大规模部署
接入交换机:可以考虑华为或者H3C的产品
- 成本控制得不错
- 基础RDMA功能都支持
系统配置:这些参数不调,性能白瞎
内核参数优化
# 修改/etc/sysctl.conf,这些参数我测试过无数遍
# 网络缓冲区大小
net.core.rmem_max = 268435456
net.core.wmem_max = 268435456
net.core.rmem_default = 67108864
net.core.wmem_default = 67108864
# TCP缓冲区
net.ipv4.tcp_rmem = 8192 87380 268435456
net.ipv4.tcp_wmem = 8192 65536 268435456
# 连接跟踪表大小
net.netfilter.nf_conntrack_max = 1048576
net.nf_conntrack_max = 1048576
# 应用生效
sysctl -pNUMA绑定配置
这个特别重要!RDMA对NUMA敏感性很高,配置不好性能直接腰斩。
# 查看NUMA拓扑
numactl --hardware
# 查看网卡所在NUMA节点
cat /sys/class/net/ib0/device/numa_node
# 绑定应用到对应NUMA节点
numactl --cpunodebind=0 --membind=0 your_applicationCPU隔离配置
# 在/etc/default/grub中添加
GRUB_CMDLINE_LINUX="isolcpus=2-15,18-31 nohz_full=2-15,18-31 rcu_nocbs=2-15,18-31"
# 更新grub配置
update-grub
reboot网卡驱动和固件:版本选择有门道
MLNX_OFED驱动安装
别用发行版自带的驱动,性能和稳定性都不行。直接上Mellanox官方的MLNX_OFED:
# 下载对应版本的MLNX_OFED
wget https://www.mellanox.com/downloads/ofed/MLNX_OFED-5.8-1.0.1.1/MLNX_OFED_LINUX-5.8-1.0.1.1-ubuntu20.04-x86_64.tgz
# 解压安装
tar -xzf MLNX_OFED_LINUX-5.8-1.0.1.1-ubuntu20.04-x86_64.tgz
cd MLNX_OFED_LINUX-5.8-1.0.1.1-ubuntu20.04-x86_64
sudo ./mlnxofedinstall --upstream-libs --dpdk
# 重启服务
sudo /etc/init.d/openibd restart固件版本选择
这是个巨坑!固件版本一定要和驱动匹配,否则各种奇怪问题。我的建议:
# 查看当前固件版本
mstflint -d /dev/mst/mt4119_pciconf0 q
# 升级固件(谨慎操作!)
mstflint -d /dev/mst/mt4119_pciconf0 -i fw-ConnectX5-rel-16_32_1010-MCX556A-ECAT_Ax-UEFI-14.25.17-FlexBoot-3.6.102.bin burn血泪教训:固件升级前一定要做好备份,我曾经因为固件不匹配把网卡刷成砖头,花了一天时间才救回来。
网络配置:这些命令你必须会
基础网络配置
# 配置IP地址(以RoCE为例)
sudo ip addr add 192.168.100.10/24 dev enp24s0f0
# 启用网卡
sudo ip link set enp24s0f0 up
# 配置路由
sudo ip route add 192.168.100.0/24 dev enp24s0f0RDMA子系统配置
# 查看RDMA设备
ibstat
rdma link show
# 配置RoCE模式
echo 'RoCE v2' | sudo tee /sys/class/infiniband/mlx5_0/ports/1/gid_type
# 查看GID表
show_gids交换机配置(以Mellanox为例)
# 进入配置模式
configure
# 配置VLAN
vlan 100
exit
# 配置接口
interface ethernet 1/1
switchport mode access
switchport access vlan 100
no shutdown
exit
# 配置RDMA相关参数
# 开启PFC(Priority Flow Control)
interface ethernet 1/1
dcb priority-flow-control enable force
dcb priority-flow-control priority 3 enable
exit
# 保存配置
copy running-config startup-config性能调优:这些技巧让你的RDMA飞起来
网卡参数调优
# 调整网卡队列数量
ethtool -L enp24s0f0 combined 8
# 调整中断合并参数
ethtool -C enp24s0f0 adaptive-rx on adaptive-tx on
# 开启网卡offload功能
ethtool -K enp24s0f0 gro on gso on tso on lro on
# 调整ring buffer大小
ethtool -G enp24s0f0 rx 8192 tx 8192应用层优化
# 设置CPU亲和性
taskset -c 2-15 your_rdma_application
# 设置进程优先级
nice -n -20 your_rdma_application
# 使用大页内存
echo 1024 > /proc/sys/vm/nr_hugepages
mount -t hugetlbfs hugetlbfs /mnt/hugepages存储相关优化
如果你在用NVMe over Fabrics,这些参数也很重要:
# 调整I/O调度器
echo noop > /sys/block/nvme0n1/queue/scheduler
# 调整队列深度
echo 128 > /sys/block/nvme0n1/queue/nr_requests
# 关闭写屏障
echo 0 > /sys/block/nvme0n1/queue/write_cache监控和故障排查:没有这些工具你就是瞎子
基础监控命令
# 查看RDMA统计信息
cat /sys/class/infiniband/mlx5_0/ports/1/counters/*
# 使用perfquery查看端口计数器
perfquery -x
# 查看网卡错误统计
ethtool -S enp24s0f0 | grep -i error
# 实时监控带宽
iftop -i enp24s0f0高级诊断工具
# 使用ibdiagnet检查IB网络
ibdiagnet -o /tmp/ibdiag_output
# 网络延迟测试
ibping -c 1000 -f mlx5_0 1
# 带宽测试
ib_send_bw -d mlx5_0 -i 1 -s 65536
ib_read_bw -d mlx5_0 -i 1 -s 65536常见问题排查
问题1:RDMA连接建立失败
# 检查GID表
show_gids
# 检查路由可达性
ibping server_ip
# 检查防火墙
iptables -L | grep 4791 # RoCE默认端口问题2:性能不达预期
# 检查CPU使用情况
top -H -p `pgrep your_app`
# 检查内存使用
cat /proc/meminfo | grep Huge
# 检查网卡中断分布
cat /proc/interrupts | grep mlx5问题3:丢包严重
# 检查PFC计数器
ethtool -S enp24s0f0 | grep pfc
# 检查缓冲区使用情况
cat /sys/class/infiniband/mlx5_0/ports/1/counters/VL15_dropped自动化运维脚本:偷懒是第一生产力
RDMA健康检查脚本
#!/bin/bash
# rdma_health_check.sh
INTERFACE="mlx5_0"
PORT="1"
echo "=== RDMA健康检查开始 ==="
# 检查设备状态
if ibstat $INTERFACE $PORT | grep -q "Active"; then
echo "✓ RDMA设备状态正常"
else
echo "✗ RDMA设备状态异常"
exit 1
fi
# 检查错误计数
ERROR_COUNT=$(cat /sys/class/infiniband/$INTERFACE/ports/$PORT/counters/port_rcv_errors)
if ; then
echo "✗ 接收错误过多: $ERROR_COUNT"
else
echo "✓ 错误计数正常: $ERROR_COUNT"
fi
# 检查温度
TEMP=$(mst status -v | grep temperature | awk '{print $2}')
if ; then
echo "✗ 网卡温度过高: ${TEMP}°C"
else
echo "✓ 网卡温度正常: ${TEMP}°C"
fi
echo "=== 健康检查完成 ==="性能基准测试脚本
#!/bin/bash
# rdma_benchmark.sh
DEVICE="mlx5_0"
SERVER_IP="192.168.100.10"
echo "开始RDMA性能测试..."
# 带宽测试
echo "1. 带宽测试"
ib_send_bw -d $DEVICE -s 65536 -t 10 $SERVER_IP
# 延迟测试
echo "2. 延迟测试"
ib_send_lat -d $DEVICE -s 1 -n 10000 $SERVER_IP
# CPU使用率测试
echo "3. CPU使用率测试"
ib_send_bw -d $DEVICE -s 65536 -t 10 --cpu_util $SERVER_IP
echo "性能测试完成"大规模部署经验:血与泪的教训
网络拓扑设计
我们公司现在有300+节点的RDMA集群,网络拓扑设计特别重要:
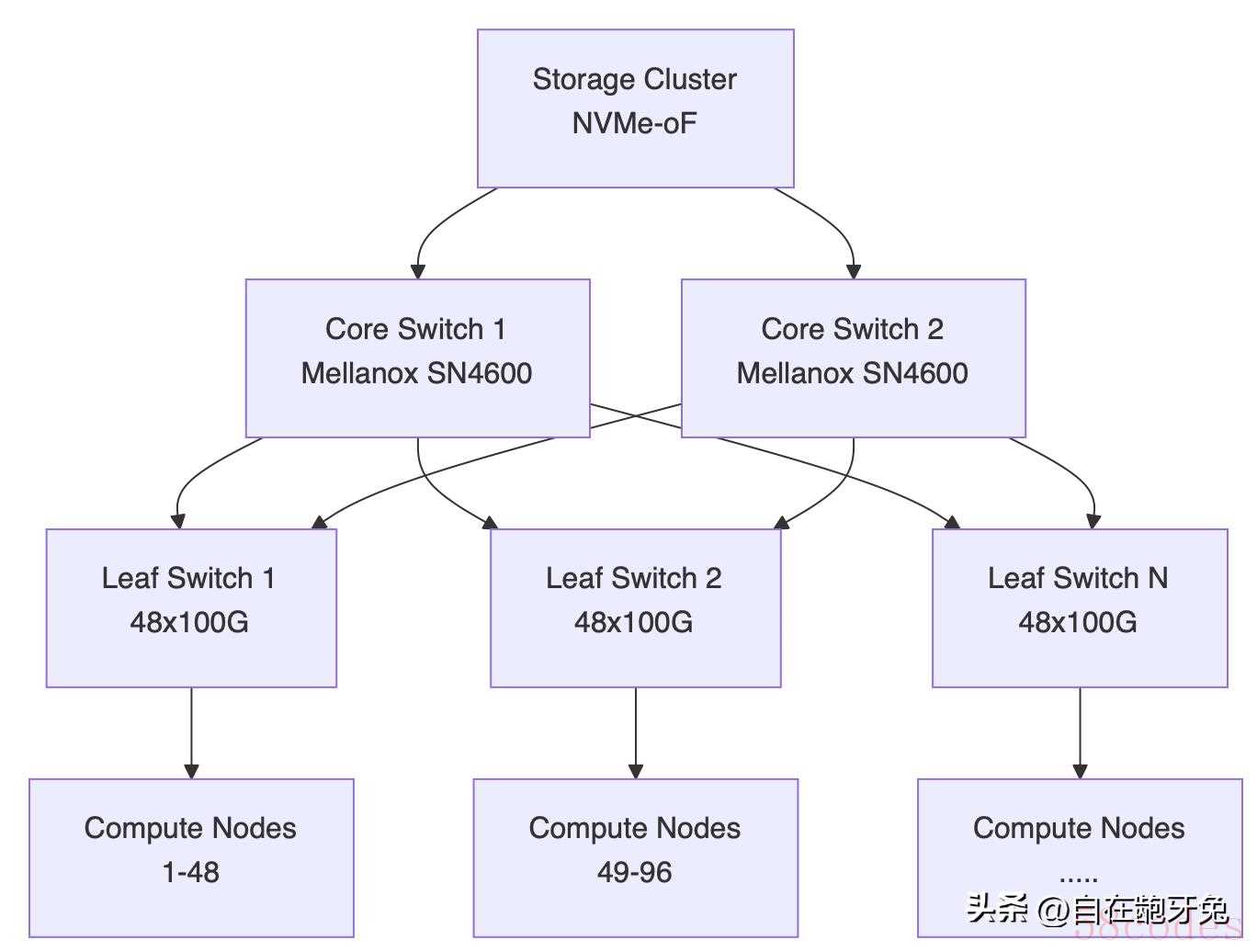
批量部署技巧
# 使用Ansible批量配置
# hosts文件
node.cluster.local
# playbook示例
---
- hosts: rdma_nodes
tasks:
- name: Install MLNX OFED
shell: ./mlnxofedinstall --upstream-libs --dpdk
- name: Configure network
template:
src: ifcfg-rdma.j2
dest: /etc/sysconfig/network-scripts/ifcfg-{{ rdma_interface }}
- name: Set kernel parameters
sysctl:
name: "{{ item.name }}"
value: "{{ item.value }}"
loop:
- { name: "net.core.rmem_max", value: "268435456" }
- { name: "net.core.wmem_max", value: "268435456" }运维自动化
# 定时健康检查
# 添加到crontab
*/10 * * * * /opt/scripts/rdma_health_check.sh >> /var/log/rdma_health.log
# 自动故障切换脚本
#!/bin/bash
if ! ibping -c 3 backup_server; then
echo "Primary RDMA link down, switching to backup..."
ip route del default via 192.168.100.1
ip route add default via 192.168.101.1
fi踩过的坑和解决方案
坑1:固件版本不匹配导致的性能下降
现象:升级驱动后,RDMA性能突然下降50%
原因:新驱动和老固件不匹配,某些硬件offload功能被禁用
解决:升级固件到匹配版本,性能立马恢复
坑2:NUMA配置不当导致延迟增加
现象:同样的应用,延迟比别人高一倍
原因:应用跑在了错误的NUMA节点上,内存访问跨NUMA
解决:严格按照网卡所在NUMA节点配置应用绑定
坑3:交换机缓冲区配置不当导致丢包
现象:大流量时丢包严重,但带宽没有跑满
原因:交换机缓冲区配置过小,PFC配置有问题
解决:调整交换机缓冲区大小,正确配置PFC优先级
坑4:电源管理导致的性能波动
现象:RDMA性能时好时坏,不稳定
原因:CPU电源管理策略导致频率波动
解决:设置CPU为performance模式
# 禁用CPU电源管理
for i in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor; do
echo performance > $i
done趋势和建议
技术发展方向
- 400G/800G时代来临:带宽继续提升,但延迟优化更重要
- GPU Direct支持更好:AI训练场景对RDMA需求更高
- 云原生RDMA:容器和K8s环境下的RDMA支持在完善
选型建议
对于新项目,我的建议是:
- 预算充足:直接上InfiniBand,性能最稳定
- 成本敏感:RoCE v2 + Mellanox网卡,性价比最高
- 兼容性要求高:考虑iWARP,但要接受性能损失
学习资源推荐
- Mellanox官方文档:技术细节最全面
- OFED源码:想深入理解原理必看
- 各大厂商的白皮书:了解最佳实践
文末:RDMA运维的核心要点
经过这几年的摸索,我总结出RDMA运维的几个核心要点:
- 硬件选择很重要:别贪便宜,好的硬件能省很多后期运维的麻烦
- 系统调优是关键:NUMA绑定、内核参数、中断亲和性,一个都不能少
- 监控要做好:没有监控就是盲人摸象,出了问题都不知道从哪查起
- 自动化是必须的:手工运维500个节点?你会疯的
- 持续学习:技术发展很快,要跟上节奏
最后想说的是,RDMA确实不好搞,坑很多,但是一旦搞好了,性能提升是实实在在的。我们的HPC集群用上RDMA后,作业完成时间缩短了30%以上,用户满意度大幅提升。
写这篇文章花了我整整一个周末,都是实战经验,没有一句废话。如果对你有帮助,记得收藏分享!
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏
