我们来分享一个关于Paimon在会员数仓运用场景的案例。
---
"案例名称:" Paimon赋能会员数仓:提升数据写入效率与查询性能
"背景:"
一家大型电商平台,随着业务规模的快速增长,其会员数据量呈指数级增长。原有的基于传统关系型数据库(如MySQL)的会员数仓架构,面临着以下挑战:
1. "写入性能瓶颈:" 每日海量的会员行为日志、会员属性变更、交易数据等需要实时或准实时地写入数仓,导致数据库写入延迟增加,高峰期甚至出现写入失败。
2. "查询性能下降:" 随着积累的数据越来越多,复杂的会员画像分析、生命周期价值计算、精准营销推荐等查询任务变得非常耗时,影响业务决策的及时性。
3. "运维复杂度高:" 传统数仓的表结构变更、分区管理、数据备份恢复等操作较为繁琐,运维成本高。
4. "成本压力:" 为了应对写入和查询压力,往往需要不断购买更昂贵的数据库硬件或增加计算资源,成本持续上升。
"目标:"
利用Paimon数据湖表技术,重构会员数仓架构,解决上述痛点,实现:
"高吞吐量写入:" 显著提升海量会员数据的写入效率。
"高性能查询:" 优化会员数据分析查询性能,缩短分析时间
相关内容:
1. 会员中台数仓的原数据架构、历史背景与痛点问题
1.1 历史背景
会员中台作为支撑全公司会员服务的核心系统, 承载着所有互联网产品的会员订阅、下单、退款、画像等关键业务。随着公司业务的快速发展, 会员数量从千万级增长到亿级, 业务场景也日益复杂, 对数据处理的实时性、准确性和灵活性提出了更高要求。 因此会员中台携手奇麟云数仓团队共同构建Paimon流批一体化数仓, 为会员数据分析、精准营销等业务场景提供更高效的数据底座。
1.2 原数据架构
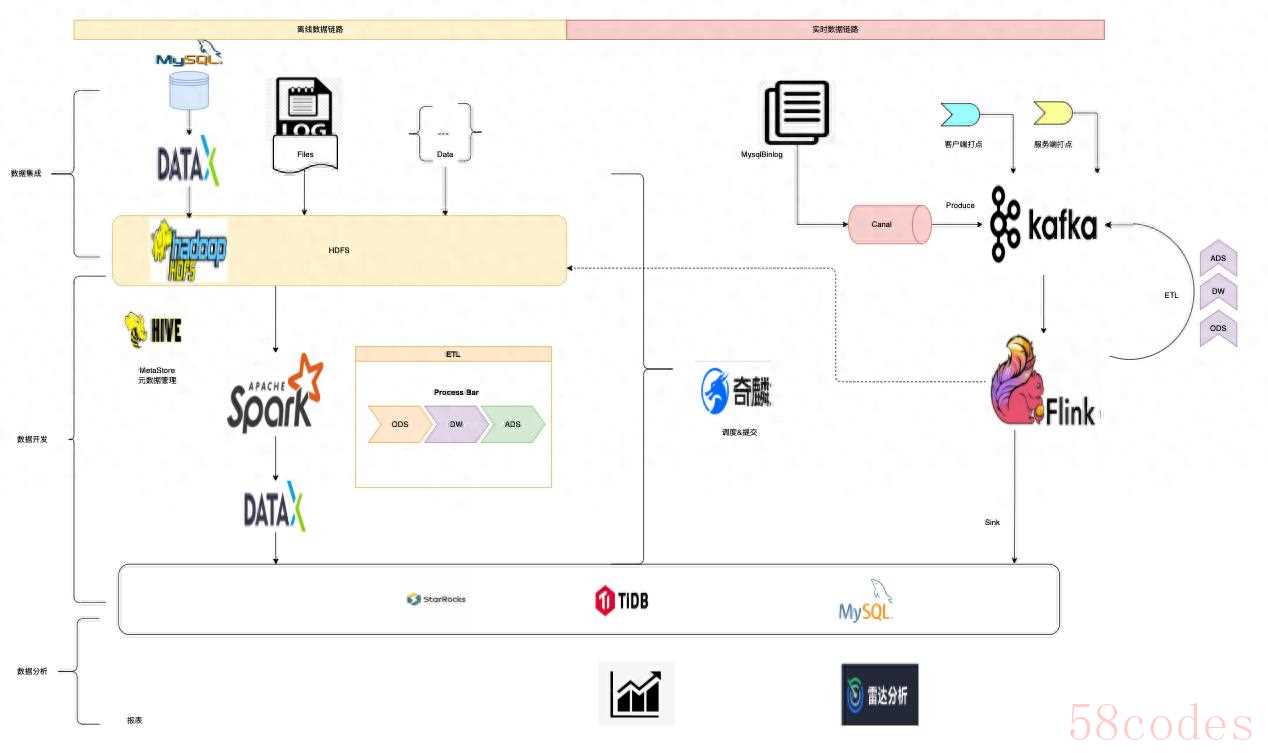
1.3 痛点问题
- 组件繁多、链路复杂: 传统Lambda架构依赖DataX、StarRocks、Canal、Zookeeper、Kafka、Flink、Spark、HDFS、Hive等众多组件构建。这种多组件架构不仅增加了系统的复杂度和潜在故障点, 还带来了较高的运维负担。同时, 技术团队需要掌握各个组件的专业知识, 这无疑提升了学习门槛和人力成本, 最终导致整体解决方案的总体拥有成本居高不下。特别是实时场景, 中间层数据不可见, 排查问题困难重重, 数据易丢失。
- 数据冗余、复用性低: 由于实时和离线链路采用不同的计算引擎, 数据无法实现共享和复用。离线场景依赖HDFS存储, 实时场景则基于Kafka构建, 同时为支持数据分析需求, 往往还需要在SR中额外维护一份明细数据。这种多源存储模式不仅造成了数据的重复存储, 还显著增加了计算和存储成本。此外, 相同的业务逻辑需要在不同链路中重复开发, 一旦需要修改逻辑就要同步更新多处代码, 严重影响了代码的可维护性和复用效率。
- 离线延迟大、实时成本高昂: 传统离线Hive数仓通过Spark调度执行ETL任务, 但Spark启动耗时较长, 通常采用T-1模式更新数据。这种滞后的数据更新机制难以及时反映运营策略效果, 影响决策效率。而实时数据处理虽然依托Kafka或StarRocks等高性能组件, 但因采用SSD存储, 成本居高不下, 只能保留短期数据。这种存储周期限制使得运营团队无法进行长期数据趋势分析, 难以制定全局性决策。
- 开发成本高: 实时链路的黑盒特性导致问题排查困难, 通常需要同步开发离线链路进行数据校验和修正, 这增加了额外的开发维护成本。
- 数据不一致: 维护实时和离线两套相同计算逻辑的代码, 在业务调整时需要同步修改, 不仅增加了维护成本, 还容易因疏忽导致修改不完整。这种重复开发的模式存在较大风险, 极易造成数据不一致, 影响数据可靠性和决策准确性。
2. Paimon的特点和数据湖架构

Apache Paimon是一个流数据湖平台, 支持Streaming实时计算能力和Lakehouse架构优势, 具备以下核心特性:
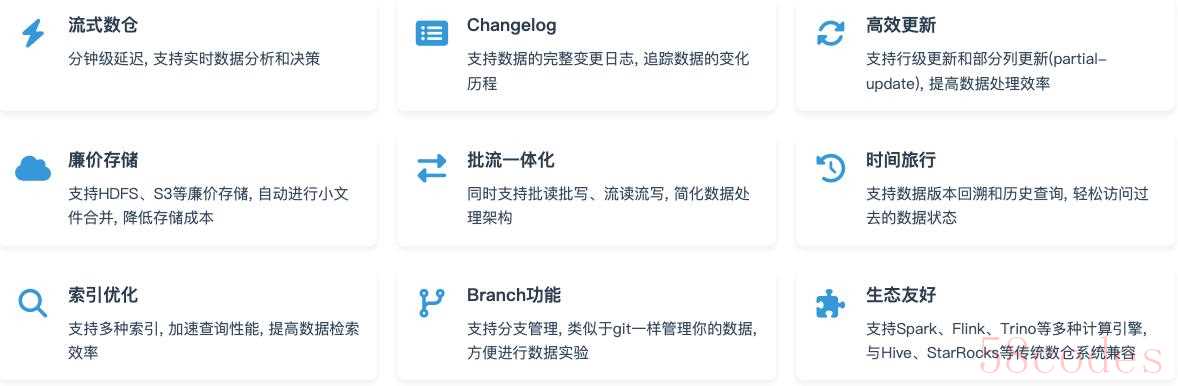
2.1 Paimon数据湖架构
引入Paimon后的会员数仓架构如下:
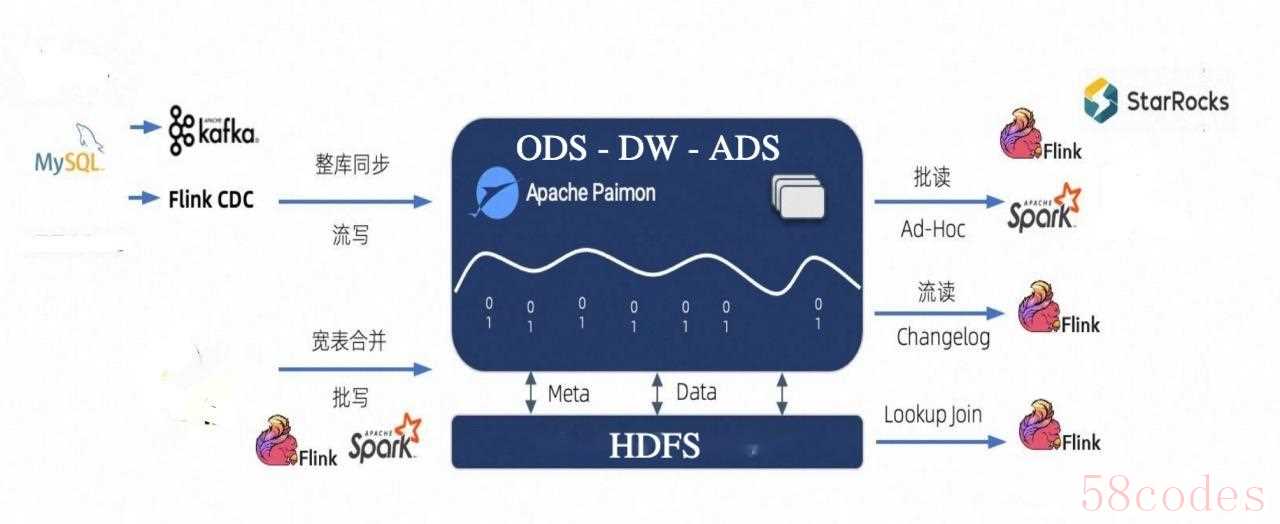
- 数据源层: 保持不变, 包括业务系统数据库、日志文件等
- 采集层: 使用Flink CDC实时采集数据库变更, Kafka接收日志数据
- 存储层: Paimon作为主存储, 存储原始数据和计算结果
- 原始数据区: 存储未经处理的原始数据
- 明细数据区: 存储清洗后的明细数据
- 聚合数据区: 存储计算后的聚合指标
- 计算层: Flink负责实时计算, Spark负责离线计算
- 服务层: 通过Trino或者StarRocks集成PaimonCatalog提供数据服务
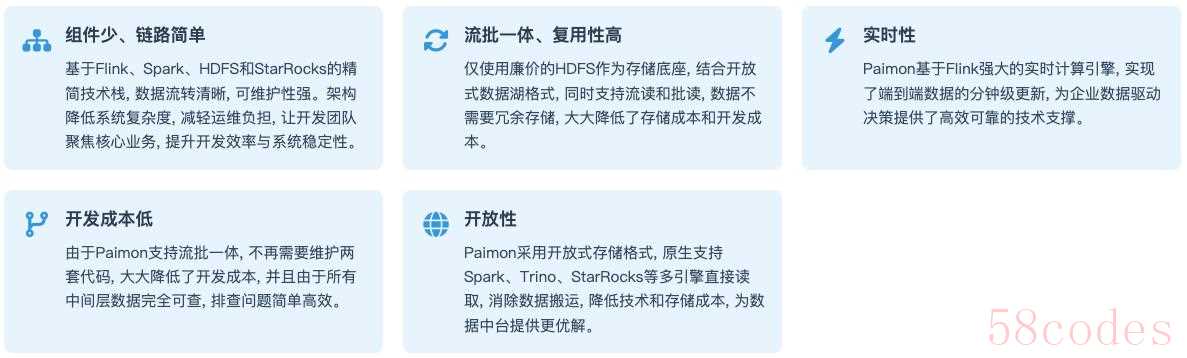
2.2 架构优势
3. 实践案例分享
3.1 案例一: 使用partial-update构建实时订单宽表
3.1.1 业务场景
需要实时整合订单信息、商品信息、设备信息、优惠券、退款信息等多维度数据, 形成大宽表, 简化数据分析难度, 这些数据来源于不同的表, 根据order_id进行关联。传统方案通常采用Flink双流Join来实现, 但存在数据延迟高、状态管理复杂、存储成本高等问题。
3.1.2 实现过程
上游数据来源
上游数据来自多个原始业务表, 这些表都是通过FlinkCDC写入到Paimon的ODS层数据, 采用deduplicate合并引擎确保数据唯一性
-- 基础订单信息表
CREATE TABLE ods.order_info (
order_id string comment '订单ID',
product string comment '所属产品名称',
qid string comment '用户id',
order_create_time timestamp(3) comment '订单创建时间',
order_end_time timestamp(3) comment '订单结束/时间',
order_status int comment '订单状态',
order_real_fee decimal(10, 2) comment '订单实付金额',
sku_id int comment '商品id',
....
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'paimon',
'merge-engine' = 'deduplicate',
.....
);
-- 订单设备信息表
CREATE TABLE ods.order_device_info (
order_id string comment '订单ID',
mid string comment '设备id',
client_type string comment '客户端类型',
android_id string comment 'android设备id',
idfa string comment 'idfa',
client_version string comment '客户端版本',
os_name string comment '操作系统名称',
ip string comment 'ip',
....
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'paimon',
'merge-engine' = 'deduplicate',
.....
);
-- 订单优惠券信息表
CREATE TABLE ods.order_coupon_info (
order_id string comment '订单ID',
coupon_code string comment '优惠券唯一码',
qid string comment '领取用户id',
coupon_batch string comment '优惠券批次码',
ctime timestamp(3) comment '优惠券领取时间',
coupon_type int comment '优惠券类型',
coupon_status int comment '优惠券状态',
coupon_discount string comment '优惠券折扣/减免值',
...
PRIMARY KEY (coupon_code) NOT ENFORCED
) WITH (
'connector' = 'paimon',
'merge-engine' = 'deduplicate',
.....
);
-- 订单退款信息表
CREATE TABLE ods.order_refund_info (
order_id string comment '订单ID',
refund_mer_trade_code string comment '退款流水号',
qid string comment '用户id',
refund_type int comment '退款类型',
refund_status int comment '退款状态',
refund_fee decimal(10, 2) comment '退款金额',
refund_time timestamp(3) comment '退款时间',
refund_way int comment '退款支付方式',
...
PRIMARY KEY (refund_mer_trade_code) NOT ENFORCED
) WITH (
'connector' = 'paimon',
'merge-engine' = 'deduplicate',
.....
);订单宽表结构定义
-- 订单宽表
CREATE TABLE dwd.enrich_order (
order_id string comment '订单ID',
-- 订单基础信息
product string comment '所属产品名称',
qid string comment '用户id',
order_create_time timestamp(3) comment '订单创建时间',
order_end_time timestamp(3) comment '订单结束/时间',
order_status int comment '订单状态',
order_real_fee decimal(10, 2) comment '订单实付金额',
sku_id int comment '商品id',
-- 订单设备信息
mid string comment '设备id',
client_type string comment '客户端类型',
android_id string comment 'android设备id',
idfa string comment 'idfa',
client_version string comment '客户端版本',
os_name string comment '操作系统名称',
ip string comment 'ip',
-- 订单优惠券信息
coupon_code string comment '优惠券唯一码',
coupon_batch string comment '优惠券批次码',
coupon_type int comment '优惠券类型',
coupon_status int comment '优惠券状态',
coupon_discount string comment '优惠券折扣/减免值',
-- 订单退款信息
g_refund_seq int comment '退款字段sequence',
refund_info array<row<refund_mer_trade_code string,
refund_type int,
refund_status int,
refund_fee decimal(10, 2),
refund_time timestamp(3),
refund_way int>> comment '退款信息',
...
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'paimon',
'merge-engine' = 'partial-update',
'write-only' = 'true',
'changelog-producer' = 'lookup',
'fields.g_refund_seq.sequence-group' = 'refund_info',
'fields.refund_info.aggregate-function' = 'nested_update',
'fields.refund_info.nested-key' = 'refund_mer_trade_code'
);关键配置说明
- partial-update合并引擎: 允许不同的流只更新表中的特定字段, 而不需要覆盖整个行
- nested_update聚合函数: 针对退款信息数组, 会将相同order_id的退款合并, 并以refund_mer_trade_code为主键进行更新
- changelog-producer=lookup: 确保下游可以以流的方式读取变更数据
- write-only模式: 优化写入性能, 配合专用的compact任务处理小文件合并和过期数据清理
FlinkSQL多流写入宽表
使用multi insert语法, 从不同数据源写入订单宽表的不同字段:
-- FlinkSQL
create catalog paimon with (
'type' = 'paimon',
'metastore' = 'hive',
'uri' = 'thrift://xxxxx',
'warehouse' = 'hdfs://xxx/paimon/warehouse'
);
use catalog paimon;
-- 使用multi insert语法写入
execute statement set begin
-- 订单基础信息字段
insert into `dwd`.`enrich_order` (`order_id`, `product`, `order_create_time`, `order_end_time`, `order_status`, `order_real_fee`, `sku_id`)
select `order_id`, `product`, `order_create_time`, `order_end_time`, `order_status`, `order_real_fee`, `sku_id`
from `ods`.`order_info` /*+ OPTIONS('scan.parallelism' = '20', 'scan.remove-normalize' = 'true', 'consumer-id' = 'dsc_dwd_enrich_order') */
;
-- 订单设备信息字段
insert into `dwd`.`enrich_order` (`order_id`, `mid`, `client_type`, `android_id`, `idfa`, `client_version`, `os_name`, `ip`)
select `order_id`, `mid`, `client_type`, `android_id`, `idfa`, `client_version`, `os_name`, `ip`
from `ods`.`order_device_info` /*+ OPTIONS('scan.parallelism' = '20', 'scan.remove-normalize' = 'true', 'consumer-id' = 'dsc_dwd_enrich_order') */
;
-- 订单优惠券信息
insert into `dwd`.`enrich_order` (`order_id`, `coupon_code`, `coupon_batch`, `coupon_type`, `coupon_status`, `coupon_discount`)
select `order_id`, `coupon_code`, `coupon_batch`, `coupon_type`, `coupon_status`, `coupon_discount`
from `ods`.`order_coupon_info` /*+ OPTIONS('scan.parallelism' = '10', 'scan.remove-normalize' = 'true', 'consumer-id' = 'dsc_dwd_enrich_order') */
;
-- 订单退款信息
insert into `dwd`.`enrich_order` (`order_id`, `g_refund_seq`, `refund_info`)
select `order_id`,
1 as `g_refund_seq`,
array as refund_info
from `ods`.`order_refund_info` /*+ OPTIONS('scan.parallelism' = '3', 'scan.remove-normalize' = 'true', 'consumer-id' = 'dsc_dwd_enrich_order') */
;
end;可见SQL内容非常直观, 每个流只关注于自己写入的字段, 没有任何Join逻辑, 代码易于理解和维护。
3.1.3 技术对比
Paimon partial-update优势
- 真正的按列更新: 使用SequenceGroup机制解决乱序问题, 实现真正的部分更新而非仅非空更新
- 低延迟更新: 无需等待所有流数据到达, 不需要进行状态管理, 实现实时更新
- 多流更新支持: 允许多个流或者批任务同时更新同一张表, 自动处理冲突
- 聚合功能: 支持在更新时进行聚合操作, 如sum、max、nested_update等
- 变更日志集成: 自动生成变更日志, 支持下游流读
- 数据可回溯: 逻辑变更, 数据可立即按需回溯更新, 无需等待状态恢复, 且不影响其他流写入
传统Flink双流Join痛点
- 数据延迟高: 需要等待两个流的数据都到达才能进行Join
- 状态管理复杂: 需要维护大量的中间状态, 容易导致内存溢出
- 数据倾斜严重: 某些key可能导致大量数据集中在一个节点
- 容错成本高: 状态快照和恢复过程开销大
- 开发复杂度高: 需要处理窗口、状态过期等多种配置
- 存储成本高: 需要存储两份原始数据流和中间状态
3.2 案例二: 使用Bitmap进行流量UV精确统计
3.2.1 业务场景
需要统计不同维度下的收银台曝光UV(独立用户数), 如按产品、会员等级、小时、天等维度组合。
3.2.2 传统实现方案
- 使用cube或grouping-sets分组方式组合各维度, 使用count(distinct mid)方式进行UV统计
- 缺点1: 维度多, cube计算量指数级增长
- 缺点2: 对于下游使用方不友好, 查询必须要指定每一个维度的值
- 缺点3: 组合不够灵活, 无法事先组合所有维度值
3.2.3 Bitmap实现方案
- 使用Bitmap数据类型进行精准去重。
- 优点1: 像sum一样可以任意组合维度进行精确去重统计。
- 优点2: 通过用 Bitmap 的一个 Bit 位表示对应下标是否存在,能节省大量存储空间。例如,对 INT32 类型的数据去重,如使用普通的 bitmap,其所需的存储空间只占 COUNT(DISTINCT expr) 的 1/32。
- 优点3: Bitmap 去重使用的是位运算,所以计算速度相较 COUNT(DISTINCT expr) 更快
- 缺点1: 非数字类型构建字典表进行数据映射再使用Bitmap, 会增加一定的开发成本
3.2.4 实现过程
构建映射字典表
使用Paimon之前, 构建Hive字典表, 将字符串类型的mid映射位bigint类型, 在每次插入新的mid时, 需要自己手动去重实现增量插入, 来保证id不变特性, 但是现在可以使用paimon first-row合并引擎轻松实现。
-- 字典表定义:
CREATE TABLE `dict`.`mid_mapping` (
`mid` STRING NOT NULL COMMENT '设备mid',
`mid_int` BIGINT COMMENT '设备mid数字类型映射',
PRIMARY KEY (`mid`) NOT ENFORCED
) COMMENT 'mid字典表'
WITH (
'merge-engine' = 'first-row',
'ignore-delete' = 'true',
...
);使用Flink实时转换ID
编写FlinkUDF实现采用雪花算法生成自增id, 再使用FlinkSQL将mid实时写入字典表, 参考雪花ID生成器
Flink UDF代码如下
package cn.qihoo360.member.udf.flink;
import com.github.yitter.contract.IdGeneratorOptions;
import com.github.yitter.idgen.YitIdHelper;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.functions.FunctionContext;
import org.apache.flink.table.functions.ScalarFunction;
import java.lang.reflect.Field;
import java.util.Random;
public class AutoIDGeneratorUDF extends ScalarFunction {
@Override
public void open(FunctionContext fc) throws Exception {
super.open(fc);
short workerId = extractTaskIndex(fc);
IdGeneratorOptions options = new IdGeneratorOptions(workerId);
options.WorkerIdBitLength = 15; // 默认值6,限定 WorkerId 最大值为2^6-1,即默认最多支持64个节点。
options.SeqBitLength = 7; // 默认值6,限制每毫秒生成的ID个数。若生成速度超过5万个/秒,建议加大 SeqBitLength 到 10
// 必须满足:WorkerIdBitLength + SeqBitLength <= 22
YitIdHelper.setIdGenerator(options);
}
@DataTypeHint("BIGINT")
public long eval() {
return YitIdHelper.nextId();
}
@Override
public boolean isDeterministic() {
return false;
}
private short extractTaskIndex(FunctionContext fc) throws Exception {
Field field = fc.getClass().getDeclaredField("context");
field.setAccessible(true);
Object context = field.get(fc);
if (context == null) {
System.out.println("AutoIDGeneratorUDF: context is null, use random int");
return (short) new Random().nextInt(Short.MAX_VALUE);
}
RuntimeContext runtimeContext = (RuntimeContext) context;
return (short) runtimeContext.getTaskInfo().getIndexOfThisSubtask();
}
}使用FlinkSQL实时写入字典表
-- FlinkSQL
create temporary function auto_id as 'cn.qihoo360.member.udf.flink.AutoIDGeneratorUDF';
insert into `dict`.`mid_mapping`
select mid,
auto_id() as mid_int
from `dwd`.`cashier_imp_event` /*+ OPTIONS('scan.parallelism' = '10', 'scan.remove-normalize' = 'true', 'consumer-id' = 'dsc_dict_mid_mapping') */
;定义下游聚合表
使用Paimon aggregation合并引擎, 聚合字段pv使用sum函数, uv_bitmap使用last_non_null_value函数(由于与StarRocks序列化不兼容问题, 无法直接使用Paimon中rbm64聚合函数)
-- FlinkSQL
create table `dws`.`cashier_imp_hi` (
dt string comment '日期',
hh string comemnt '小时',
product string comment '产品名称',
pv int comment '收银台曝光PV',
uv_bitmap varbinary comment '收银台曝光UV(Bitmap)',
primary key (`dt`, `hh`, `product`) not enforced
) comment '收银台曝光流量统计'
partitioned by (`dt`, `hh`)
with (
'merge-engine' = 'aggregation',
'fields.pv.aggregate-function' = 'sum',
-- 由于paimon原生的Bitmap和StarRocks的Bitmap序列化问题, 无法直接使用rbm64聚合函数
'fields.uv_bitmap.aggregate-function' = 'last_non_null_value'
);使用Spark进行聚合加工
因为StarRocks官方提供了Bitmap相关的HiveUDF jar, 所以采用Spark计算, 可以直接使用这些UDF。当然也可以采用FlinkSQL来聚合,但是就必须自己开发FlinkBitmapUDF了。 写入前关联字典表, 获取数字类型的mid_int, 聚合为Bitmap数据类型。
-- SparkSQL
set spark.sql.sources.partitionOverwriteMode=dynamic;
insert overwrite table `dws`.`cashier_imp_hi` partition(dt)
select dt,
hh,
product,
sum(1) as pv,
bitmap_agg(t2.mid_int) as uv_bitmap
from `dwd`.`cashier_imp_event` t1
left join `dict`.`mid_mapping` t2 on t1.mid = t2.mid
where coalesce(t1.mid, '') != ''
group by 1, 2, 3
;使用StarRocks进行OLAP查询
按照StarRocks文档教程, 创建PaimonCatalog来查询paimon表。使用Bitmap函数即可灵活的获取不同维度组合的UV数据, 非常方便高效。 并且推荐结合物化视图功能,可进一步加速查询。
-- StarRocksSQL
-- 在StarRocks中创建Paimon Catalog
select dt,
hh,
product,
sum(pv) as pv,
bitmap_union_count(bitmap_from_binary(uv_bitmap)) as uv
from paimon.dws.cashier_imp_hi
group by 1, 2, 3;3.3 案例三: 使用Branch功能进行数据修正
3.3.1 业务场景
因为流任务的特性,数据一旦写入后如果维度更新或者源数据流顺序问题,都会导致实时数据会有一定的不准确性。 传统解决方案需要维护一个离线批任务进行验证和修正,这会增加额外的开发工作,需要维护两套代码和数据。 当前会员退款实时宽表就存在这个问题。
3.3.2 Paimon Branch功能优点
3.3.3 具体方案
步骤1: 创建streaming分支,用于实时任务写入,并指定为fallback分支
设置为fallback分支后, 当查询的分区在主分支不存在时,paimon reader会从streaming分支获取数据
-- FlinkSQL
-- 创建streaming分支
CALL sys.create_branch('dwd.enrich_refund', 'streaming');
-- 添加streaming分支为fallback分支
ALTER TABLE `dwd.enrich_refund` SET (
'scan.fallback-branch' = 'streaming'
);步骤2: Flink实时任务写入streaming分支
可以仅从最新分区开始写入, 无需全量回溯
-- FlinkSQL
insert into `dwd`.`enrich_refund$branch_streaming`
select refund_mer_trade_code,
date_format(refund_time, 'yyyy-MM-dd') as dt,
order_id as refund_order_id,
refund_time,
qid,
refund_status,
....
from dwd.enrich_order /*+ OPTIONS('scan.parallelism' = '40', 'consumer-id' = 'dsc_dwd_enrich_refund') */
cross join unnest(refund_info) as t(refund_mer_trade_code,
refund_time,
refund_status,
....)
where refund_time ≥ timestamp '${dt}'
;步骤3: Flink离线批任务写入主分支,增量修正数据
与实时任务保持相同的SQL代码逻辑,T-1调度执行,增量修正T-1分区数据
-- FlinkSQL
set 'execution.runtime-mode' = 'batch';
insert into `dwd`.`enrich_refund`
select refund_mer_trade_code,
date_format(refund_time, 'yyyy-MM-dd') as dt,
order_id as refund_order_id,
refund_time,
qid,
refund_status,
....
from dwd.enrich_order /*+ OPTIONS('scan.parallelism' = '40') */
cross join unnest(refund_info) as t(refund_mer_trade_code,
refund_time,
refund_status,
....)
where dt < '${dt}'
;步骤4: 查询数据验证
使用StarRocks或者Trino查询数据,验证是否可以查询到实时数据
-- StarRocksSQL
select dt, count(1) from paimon.dwd.enrich_refund
where dt >= date_sub(current_date, interval 3 day)
group by 1 order by 1;
-- 结果如下 (当前日为2025-09-03, 非真实数据)
-- +------------+----------+
-- | dt | count(1) |
-- +------------+----------+
-- | 2025-09-01 | 50 |
-- | 2025-09-02 | 61 |
-- | 2025-09-03 | 11 |
-- +------------+----------+验证查询paimon.dwd.enrich_refund可发现离线数据和实时数据均可以查询,并会进行合并。
4. 收益和挑战
4.1 交易域数仓升级效果
| 项 | 升级前 | 升级湖仓架构后 |
| 任务数 |
| Flink任务30+,Spark任务10,总数据量不足100TB |
| 时效性 | 80%离线数据T-1,实时数据10分钟 | 10分钟 |
| 组件费用 | 6台CVM用于部署Canal等组件费用 | 无 |
| 存储成本 | 每日增量430GB | zstd高压缩率,每日增量350GB |
| 计算成本 | 28000GB/月 | 15000GB/月 |
仅交易域数仓可降低总成本48%,并且开发效率提升30%~50%
4.2 流量域数仓升级效果
| 项 | 传统架构、按数据量预估 | 采用Paimon湖仓架构实际消耗 |
| 时效性 | T-1 | 3分钟 |
| 存储 | 预计增量10TB/日 | 采用zstd高压缩率,实际每日增量5TB |
| 计算 | 预计消耗40000GB/月 | 实际消耗28000GB/月 |
流量域数仓预计可降低总成本30%
4.3 Paimon当前面临的挑战
生态完善度: 相比Hive、Spark等成熟生态, Paimon的周边工具和集成方案还不够丰富
学习曲线: 对于习惯传统数仓架构的团队, 需要更多的Flink、Spark和存储的知识储备, 需要一定时间学习和适应
非秒级实时: 当前实时性取决于flink checkpoint间隔, 数据无法达到秒级延迟更新
LookupJoin能力欠缺: 如果需要使用LookupJoin一张超大表或者频繁更新的实时表,当前还是需要借助于HBase或者Redis这类KV数据库
文档和社区支持: 文档不够丰富,缺少一些详细的使用案例和最佳实践, 社区响应速度有待提高
5. 未来展望
5.1 技术优化方向
- 性能优化: 持续打磨参数配置,深度挖掘Paimon特性价值,提升读写与查询效率
- 生态完善: 深化与Spark、Flink、StarRocks等主流计算引擎的技术融合
- 推广落地: 推进方案在多业务场景的规模化应用,形成可复用的最佳实践
5.2 团队能力建设
- 技术深耕: 系统化研习Flink、Spark等计算引擎,深化对Paimon的底层认知
- 知识沉淀: 构建完善的文档体系,输出多场景实践案例,降低技术复用门槛
- 团队建设: 提升团队整体技术素养,打造流批一体化数据处理能力团队。
通过 Paimon 的深度引入,会员中台数仓实现了从离线批处理到实时流计算的跨越式升级,构建起 "流批一体、存算融合" 的数据处理体系,为会员画像分析、实时营销决策等核心业务场景提供分钟级响应的高效数据支撑与灵活架构保障。尽管当前在大规模并发场景下仍存在部分优化空间,但依托 Paimon 持续迭代的分层存储架构、智能索引机制及社区生态的蓬勃发展,其正加速成为企业级数据湖存储的主流技术选择。
另外值得关注的是,奇麟云数仓已正式上线全链路 Paimon 湖仓开发产品能力,欢迎联系我们体验。欢迎技术同仁及业务团队通过实际场景验证,共同探索流批一体化数据架构的更多可能。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏
