Spring AI Alibaba Graph Workflow 是一个基于 Spring AI 的图工作流框架,用于处理和分析图数据。以下是一个快速入门示例,展示如何使用 Spring AI Alibaba Graph Workflow 创建一个简单的图工作流。
### 1. 添加依赖
首先,在项目的 `pom.xml` 文件中添加 Spring AI Alibaba Graph Workflow 的依赖:
```xml
### 2. 创建图节点
定义一个简单的图节点类,表示图中的节点:
```java
public class GraphNode {
private String id;
private String name;
// 构造函数、getter 和 setter
public GraphNode(String id, String name) {
this.id = id;
this.name = name;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
相关内容:
Spring AI Alibaba Graph 是 Spring AI Alibaba 生态中的工作流与多智能体编排框架。它借鉴了 LangGraph 等框架的设计理念,并深度融合了 Spring 生态及阿里云服务,旨在帮助开发者,特别是 Java 技术栈的团队,更高效地构建复杂 AI 应用。
Spring AI Alibaba Graph 中的 StateGraph 是一个核心组件,它允许你通过图(Graph) 的形式来编排复杂的工作流或多智能体(Multi-Agent)应用。你可以把它想象成一个流程图,其中每个节点(Node)代表一个处理步骤(比如调用大模型、处理数据或等待用户输入),而边(Edge)则定义了这些步骤之间的执行顺序和条件流转。
本文将创建一个 StateGraph Bean 来描述工作流逻辑。
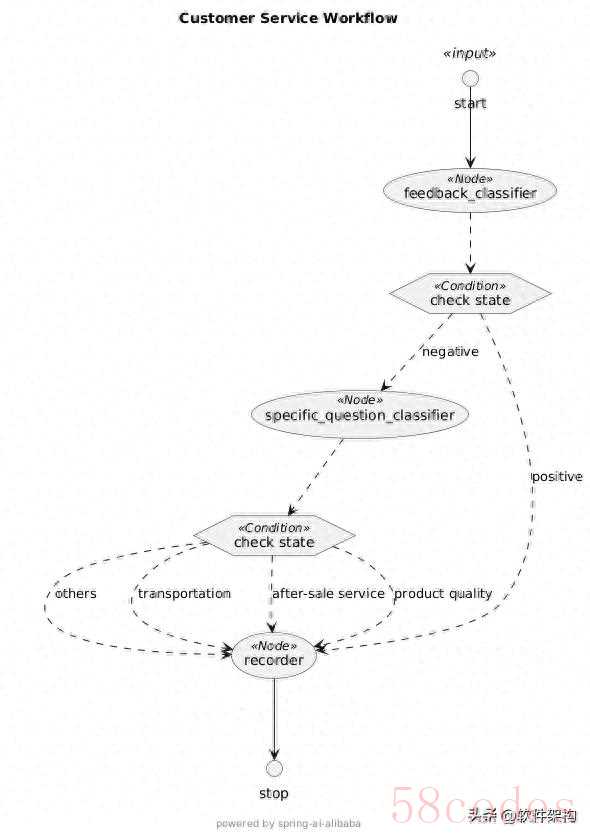
一、创建工作流StateGraph
使用 StateGraph 的 API,将前面创建的节点加入图中,并设置节点间的跳转关系:
// == 状态图构建与流转定义 ==
// 命名:便于调试/监控时识别该工作流实例
StateGraph graph = new StateGraph("Consumer Service Workflow Demo", stateFactory)
// 注册节点(异步执行包装)
.addNode("feedback_classifier", node_async(feedbackClassifier))
.addNode("specific_question_classifier", node_async(specificQuestionClassifier))
.addNode("recorder", node_async(recorderNode))
// 起始边:入口 -> 正负反馈分类
.addEdge(StateGraph.START, "feedback_classifier") // 起始节点
// 条件跳转1:依据正负反馈结果路由
// Map 键: "positive" / "negative"
.addConditionalEdges("feedback_classifier",
edge_async(new FeedbackQuestionDispatcher()),
Map.of("positive", "recorder", "negative", "specific_question_classifier"))
// 条件跳转2:细分类别全部汇聚到 recorder
.addConditionalEdges("specific_question_classifier",
edge_async(new SpecificQuestionDispatcher()),
Map.of("after-sale service", "recorder",
"transportation", "recorder",
"product quality", "recorder",
"others", "recorder"))
// 结束:记录完成后结束流程
.addEdge("recorder", StateGraph.END); // 结束节点
// 添加PlantUML打印
GraphRepresentation representation = graph.getGraph(GraphRepresentation.Type.PLANTUML,
"Customer Service Workflow");
System.out.println("
=== Customer Service Workflow UML ===");
System.out.println(representation.content());
System.out.println("=== End of UML ===
");
// 返回未编译的图;调用方(或初始化阶段)可执行 graph.compile() 生成 CompiledGraph 以便高频调用
return graph;上述配置完成了工作流图的搭建:首先将节点注册到图,并使用 node_async(...) 将每个 NodeAction 包装为异步节点执行(提高吞吐或防止阻塞,具体实现框架已封装)。
然后定义了节点间的边(Edges)和条件跳转逻辑:
START -> feedback_classifier:特殊的 START 状态直接进入初始 反馈分类(feedback_classifier)节点;
feedback_classifier -> recorder 或 ->
specific_question_classifier:通过 条件边根据分类结果选择下一步。这里使用
FeedbackQuestionDispatcher 实现 EdgeAction 来读取分类输出并返回 "positive" 或 "negative" 字符串,分别映射到后续节点;
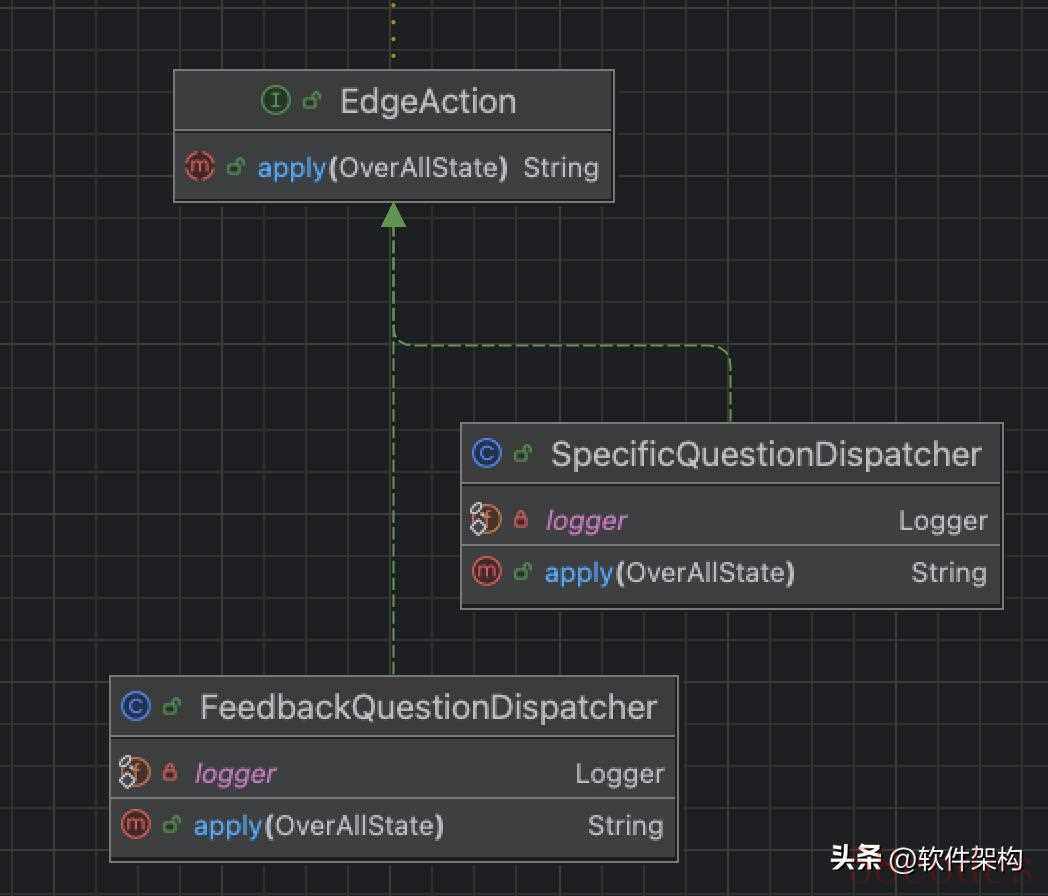
FeedbackQuestionDispatcher 类和
SpecificQuestionDispatcher 类的代码在下面提供。
specific_question_classifier -> recorder:同样通过条件边,无论负面反馈被细分为何种类别(售后、运输、质量或其它),都汇流到 记录(recorder)节点进行统一处理;
recorder -> END:最后记录节点执行完毕,进入终止状态 END,结束整个流程。
完成上述定义后,将配置类中构建的 StateGraph Bean 注入 Spring 容器即可。框架会在运行时根据此定义自动编译图并等待被调用执行。
最后一段代码的作用是打印输出PlantUML:
- 调用 graph.getGraph(GraphRepresentation.Type.PLANTUML, "Customer Service Workflow") 生成当前状态图的 PlantUML 表示对象,用于可视化理解工作流的节点与边。
- representation.content() 获取实际的 PlantUML 文本内容并打印,前后用分隔行包裹,仅用于调试或文档输出。
- 打印操作是即时的,不影响图本身的执行逻辑。
- 返回的是尚未编译的 StateGraph 实例;如果后续需要高频执行,应调用 graph.compile() 得到 CompiledGraph,以减少运行期开销(如重复解析结构等)。
- 选择在这里打印而不在编译后打印,有利于在应用启动时快速验证拓扑结构是否符合预期。
二、实现边的调度逻辑(EdgeAction)
两个分类节点之间的转接逻辑由
FeedbackQuestionDispatcher 和
SpecificQuestionDispatcher 来完成。它们实现了 EdgeAction 接口,作用是在节点执行完后读取全局状态,决定下一步该走哪条边。
FeedbackQuestionDispatcher(用于 feedback_classifier 节点之后)会检查 classifier_output 字符串,包含“positive”则返回 "positive",否则一律返回 "negative"。
因此,StateGraph 将 ”positive”映射到recorder 节点,”negative”映射到
specific_question_classifier` 节点。
FeedbackQuestionDispatcher 核心流程:
FeedbackQuestionDispatcher 类实现 EdgeAction,用于在状态图的边上决策下一步走向逻辑。
- 从全局状态 OverAllState 中读取键 classifier_output(可能不存在,若缺失用空串)。
- 记录该值到日志,便于调试。
- 根据内容简单路由:只要包含子串 positive 就返回 "positive",否则返回 "negative"。
- 返回的字符串通常作为图中下一条边或下一个节点的标识。
/**
* 根据全局状态中的分类结果决定图中接下来走向的边标识。
* 约定: 若 classifier_output 包含子串 "positive" 则走向 "positive" 分支, 否则走向 "negative"。
*/
public class FeedbackQuestionDispatcher implements EdgeAction {
/** 日志记录分类原始输出, 便于调试与问题追踪 */
private static final Logger logger = LoggerFactory.getLogger(FeedbackQuestionDispatcher.class);
/**
* 从 OverAllState 中读取键 classifier_output 的值并做简单的包含判断路由。
* @param state 全局状态容器, 通过 key 访问前置节点写入的中间结果
* @return 下一条边的标识 (positive 或 negative)
*/
@Override
public String apply(OverAllState state) throws Exception {
// value 返回 Optional, 若不存在则使用空字符串避免空指针
String classifierOutput = (String) state.value("classifier_output").orElse("");
logger.info("classifierOutput: {}", classifierOutput);
// 简单规则: 只要包含 "positive" 视为正向
if(classifierOutput.contains("positive")) {
return "positive";
}
return "negative";
}
}
FeedbackQuestionDispatcher 与 RecordingNode 的关系:两者配合实现了AI工作流中的分支控制和数据处理功能,
FeedbackQuestionDispatcher 决定路径,RecordingNode 处理数据。
- FeedbackQuestionDispatcher:负责路由决策,决定工作流走向
- RecordingNode:负责数据记录,处理和传递分类结果
SpecificQuestionDispatcher 核心流程:
- 从 OverAllState 中读取 key classifier_output 的值(用 Optional,缺省回退为空串,避免空指针)。
- 打日志输出原始分类结果,便于调试。
- 构建一个关键词到分支名的映射(当前键和值相同:after-sale、quality、transportation)。
- 依次判断分类结果字符串是否包含任一关键词,命中即返回对应分支名。
- 若全部不匹配,返回兜底分支 others。
/**
* SpecificQuestionDispatcher
*
* 根据全局状态中的 `classifier_output` 文本内容,判断所属的细分类目并返回对应的边标识。
* 匹配策略: 只要输出中包含预定义关键词子串 (after-sale / quality / transportation) 即路由到该分支;
* 若都不匹配则返回回退分支 `others`。
*/
public class SpecificQuestionDispatcher implements EdgeAction {
/** 记录分类原始输出,便于调试和问题追踪 */
private static final Logger logger = org.slf4j.LoggerFactory.getLogger(SpecificQuestionDispatcher.class);
/**
* 读取全局状态中的分类结果并进行关键词匹配路由。
* @param state OverAllState 全局状态容器,前序节点已写入 key: classifier_output
* @return 下游边标识: after-sale / quality / transportation / others
* @throws Exception 按接口约定声明(当前实现不抛出)
*/
@Override
public String apply(OverAllState state) throws Exception {
// 安全读取:缺失时退回空串,避免 NPE
String classifierOutput = (String) state.value("classifier_output").orElse("");
logger.info("classifierOutput: {}", classifierOutput);
// 关键词 -> 分支标识 映射;当前键与值相同,后续若需要展示名称或合并同义词可在此调整
Map<String, String> classifierMap = new HashMap<>();
classifierMap.put("after-sale", "after-sale");
classifierMap.put("quality", "quality");
classifierMap.put("transportation", "transportation");
// 顺序遍历:命中首个包含的关键词即返回对应分支
for(Map.Entry<String, String> entry : classifierMap.entrySet()) {
if(classifierOutput.contains(entry.getKey())) {
return entry.getValue();
}
}
// 兜底分支:未识别到任何已知关键词
return "others";
}
}现在,各组件协同完成了一个两级分类流程:首先判断评价正负,其次细分负面问题,最后输出处理方案。这种解耦的设计使开发者可以轻松地调整每个环节,例如替换分类模型、更改分类粒度,或在负面反馈流程中增加其他处理步骤(发送告警、存储数据库等),而无需影响整体架构。

 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏
