我们来学习一下 MediaCrawler 的 Bilibili (B站) 爬取功能。MediaCrawler 是一个功能强大的网络媒体内容爬取工具,它支持多种平台,包括 Bilibili。
"MediaCrawler 简介"
MediaCrawler 是一款开源 (通常是 MIT 或类似许可) 的桌面应用程序,由 Go 语言编写。它的主要目标是帮助用户从互联网上下载视频、音频、图片等内容。它支持多种网站,包括但不限于 YouTube、Vimeo、Bilibili、Facebook、Twitter 等。
"MediaCrawler 的 B站爬取功能"
MediaCrawler 的 B站爬取功能是其众多功能中的一个,它允许用户通过输入 B站视频的链接或弹幕视频链接,来搜索并下载视频。
"以下是使用 MediaCrawler 爬取 B站视频的基本步骤:"
1. "下载并安装 MediaCrawler"
首先,你需要从 MediaCrawler 的官方网站或 GitHub 仓库下载并安装该软件。由于国内访问 GitHub 可能存在困难,你可能需要借助一些工具。
2. "启动 MediaCrawler"
安装完成后,启动 MediaCrawler。你会看到一个简洁的界面,其中包含多个功能模块。
3. "选择 B站爬取功能"
在 MediaCrawler 的主界面中,找到并选择“B站爬取”或类似的选项。这通常会在“下载”或“搜索”相关的模块下。
4. "输入
相关内容:

背景
最近在github发现了一个比较火的项目——微舆,微舆是一个从0实现的创新型多智能体舆情分析系统,帮助大家破除信息茧房,还原舆情原貌,预测未来走向,辅助决策。用户只需像聊天一样提出分析需求,智能体开始全自动分析国内外30+主流社媒与数百万条大众评论。

github地址
本篇文章先不介绍它的架构。主要介绍这个项目的对于B站数据抓取的实现。
微舆这个项目对于数据获取,主要是基于另一个开源项目MediaCrawler实现。MediaCrawler是一个功能强大的多平台自媒体数据采集工具,支持小红书、抖音、快手、B站、微博、贴吧、知乎等主流平台的公开信息抓取。这个项目是由python3搭建的,需要3.11以上。还需要安装Node.js,版本>= 16.0.0。

github地址
技术原理
- 核心技术:基于 Playwright 浏览器自动化框架登录保存登录态。
- 无需JS逆向:利用保留登录态的浏览器上下文环境,通过 JS 表达式获取签名参数。
- 优势特点:无需逆向复杂的加密算法,大幅降低技术门槛。
最近发现,小红书和抖音都有点问题。B站的爬取比较稳定。
B站爬取的主要流程
下面我们来看一下它的B站爬取的主要逻辑。
一 首先判断是否需要使用代理IP。(默认没有使用)
开启的话,代码中有kuaidaili(快代理)和wandouhttp(豌豆代理)两种代理池,默认用了kuaidaili,也可以继承ProxyProvider自定义新的代理池。并且用apifox echo进行验证。
二 然后根据配置决定使用CDP模式还是标准模式启动浏览器。配置默认用的CDP模式。
- 标准模式:使用Playwright直接启动浏览器
- CDP模式:通过Chrome DevTools协议连接到浏览器实例,提供了更细粒度的控制能力
三 创建浏览器上下文并访问B站首页
四 初始化B站客户端并检查连接状态(必要时执行登录(页面扫码))
五 根据配置的爬虫类型执行不同的爬取任务:
- 搜索模式:执行搜索功能
- 详情模式:获取指定视频信息
- 创作者模式:根据CREATOR_MODE设置决定是获取创作者视频还是详情
爬取视频/帖子的数量控制是5;
每天爬取视频/帖子的数量是1;
单个视频/帖子最大爬取评论数是100;
单个视频/帖子最大爬取动态数是50
爬取时间间隔是2s
支持二级评论(需要开启ENABLE_GET_SUB_COMMENTS)
六 所有任务完成后结束程序
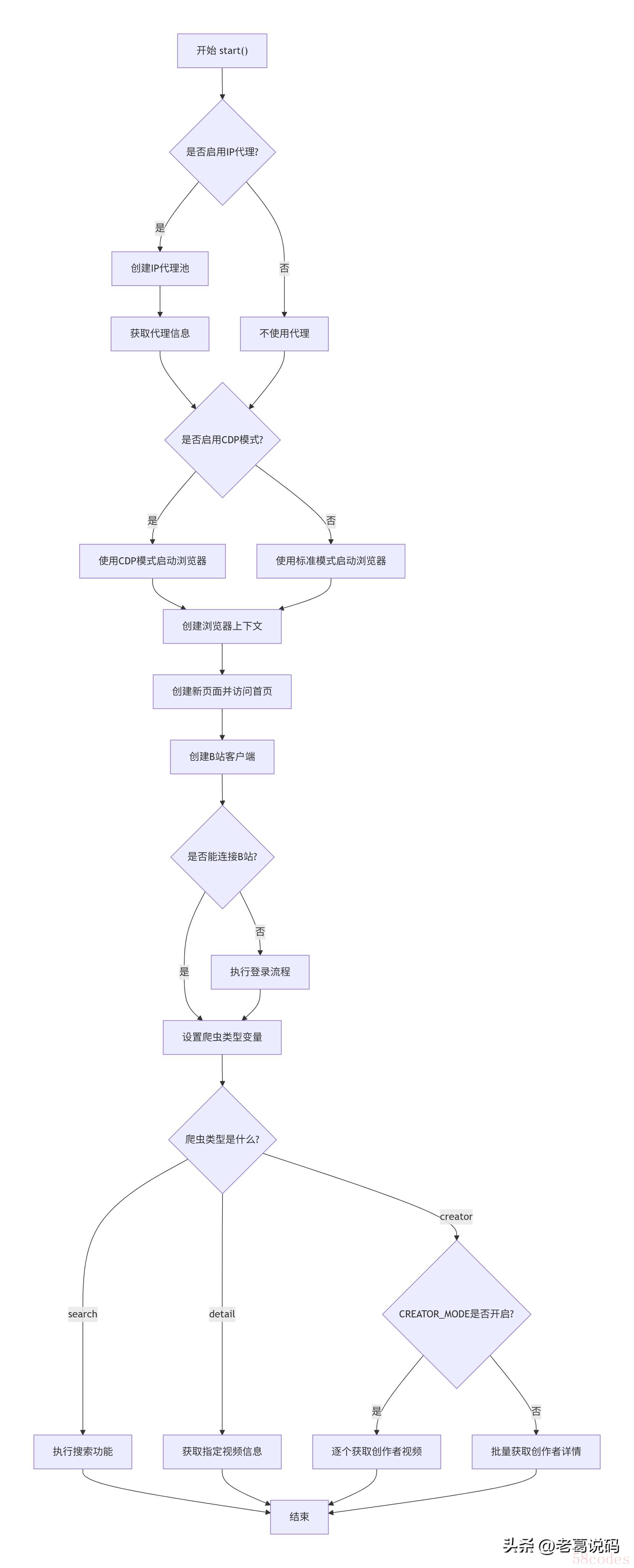
流程图
查询主要是调用B站的API。首先需要登陆后回写cookie,当调用查询时,需要带着这个cookie才能鉴权;然后还需要验签,这里可以参照另一个大神的分享。
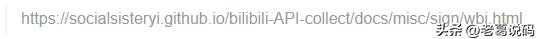
签名地址
验签逻辑:动态获取img_key和sub_key,然后通过密码表map_table进行转义,截取32位后,生成一个盐。再用参数加时间戳加盐,MD5后生成签名。
加了鉴权后,我们就能愉快的调用B站的api了。至此,抓取的主要逻辑都介绍完了。具体的代码,大家可以拉取git上的源码,进行学习。注意,本代码仅供学习和研究目的使用哦!
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏
