在构建企业RAG(Retrieval-Augmented Generation)应用时,对知识文档进行处理时引入“问答对”(Question-Answer Pair)提取,主要是基于以下几个关键原因:
1. "提升检索的准确性和相关性 (Improved Retrieval Accuracy and Relevance):"
"直接关联:" 问答对直接将特定的问题与对应的答案片段或句子关联起来。这使得在用户提出问题时,检索系统可以更精确地定位到包含答案原文的上下文,而不是仅仅返回可能相关的文档段落。
"减少歧义:" 相比于从海量的文档段落中进行检索,基于问答对进行检索可以大大减少结果集的规模,并直接聚焦于问题的核心答案,降低了因上下文不明确或理解偏差导致的误检。
2. "增强生成模型的上下文和答案质量 (Enhanced Context and Answer Quality for Generation Models):"
"明确的答案源:" RAG模型通常先检索相关文档,然后将检索到的内容作为上下文输入给生成模型(如LLM)。问答对提取提供了"预先验证过"的、与问题直接对应的答案片段。这为生成模型提供了更直接、更可靠的答案来源。
"减少冗余和噪音:" 生成的回答可以基于问答对中的精确答案,避免了在原始文档中重新“挖掘”或“总结”答案可能引入的冗余信息或错误信息。这有助于
相关内容:
前言
在 RAG(检索增强生成)系统的文档处理流程中,常规的方法其实就是对文档内容进行分段分割成文本块即可,但很多产品中经常会有另一个选项,就是对文档进行问答对的提取;小伙伴们今天老顾就来讲讲两者之间的差异,为什么有这个选项,以及如何进行运用?
结构化 vs 非结构化
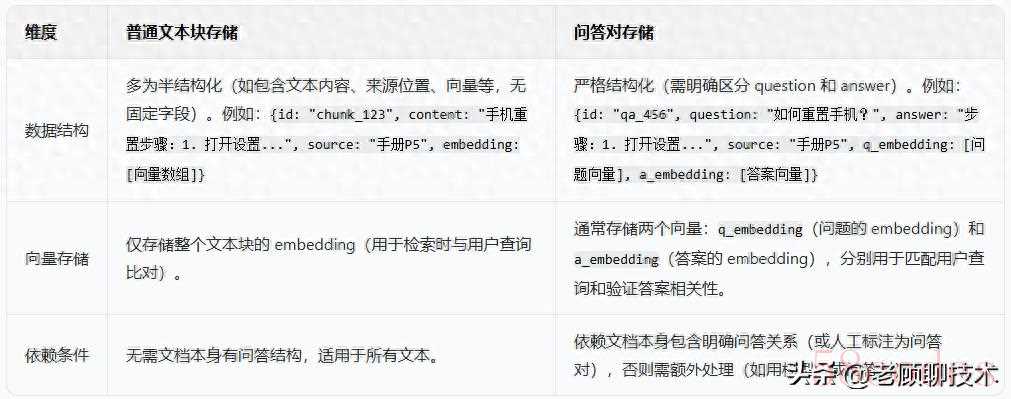
- 普通文本块:拆分后是连续的文本片段(如 “章节片段”“语义段落”),属于非结构化数据,存储和检索时需基于整体文本的语义进行匹配。
- 问答对:拆分后是明确的(question, answer)键值对,属于结构化数据,存储和检索时可针对性地对 “问题” 和 “答案” 分别处理。
存储逻辑的差异
检索逻辑的差异
检索的核心目标是:用户输入查询后,系统快速找到与查询最相关的内容。两种拆分方式的检索路径不同:

案例对比
以 “手机说明书中的重置步骤” 为例,对比两种方式的存储和检索过程。
场景:
文档原文片段:
问:如何重置手机?
答:重置手机需完成以下步骤:1. 打开 “设置”;2. 选择 “系统”;3. 点击 “重置”;4. 确认 “恢复出厂设置”。
注意:重置前请备份数据,避免丢失。
1. 普通文本块拆分
- 存储:
按语义拆分为 1 个文本块(假设),存储结构:
{
"id": "chunk_001",
"content": "问:如何重置手机?答:重置手机需完成以下步骤:1. 打开“设置”;2. 选择“系统”;3. 点击“重置”;4. 确认“恢复出厂设置”。注意:重置前请备份数据,避免丢失。",
"source": "说明书P10",
"embedding": // 整个文本的向量
}- 检索:
用户查询:“怎么重置我的手机?” - 步骤 1:生成查询的 embedding。
- 步骤 2:与所有文本块的 embedding 比对,发现chunk_001的语义最相关(包含问题和答案)。
- 步骤 3:将chunk_001的 content 输入 LLM,LLM 需从混合了问题、答案、注意事项的文本中提取核心步骤,生成。
2. 问答对拆分
- 存储:
拆分为 1 个问答对,存储结构:
{
"id": "qa_001",
"question": "如何重置手机?",
"answer": "重置手机需完成以下步骤:1. 打开“设置”;2. 选择“系统”;3. 点击“重置”;4. 确认“恢复出厂设置”。注意:重置前请备份数据,避免丢失。",
"source": "说明书P10",
"q_embedding": , // 问题“如何重置手机?”的向量
"a_embedding": // 答案的向量
}- 检索:
用户查询:“怎么重置我的手机?” - 步骤 1:生成查询的 embedding。
- 步骤 2:与所有问答对的q_embedding比对,发现qa_001的 question(“如何重置手机?”)与查询语义高度相似(均围绕 “重置手机的方法”)。
- 步骤 3:提取qa_001的 answer,并用a_embedding二次验证(确认答案确实包含 “重置步骤”)。
- 步骤 4:直接将 answer 输入 LLM(或仅做简单整理),生成(无需从混合文本中提取信息)。
基于全文检索的 question 匹配
存储逻辑
- 核心:不对 question 做 embedding,而是为 question 建立全文索引(如基于倒排索引),保留 question 的原始文本和对应的 answer(answer 可选择是否存储 embedding,用于后续过滤)。
存储结构(以数据库为例):
{
"id": "qa_001",
"question": "如何重置手机?", // 原始文本,用于全文检索
"answer": "重置步骤:1. 打开设置...",
"answer_embedding": , // 可选:用于answer的二次验证
"keywords": // 可选:手动/自动提取关键词,增强检索
}
- 索引构建:
使用全文检索引擎(如 Elasticsearch、Solr,或轻量的 Whoosh、SQLite 的全文搜索扩展)对question字段建立索引,支持分词(如中文分词器 IK)、同义词扩展(如 “重置”=“恢复出厂设置”)、模糊匹配等。
查询逻辑
用户查询 → 全文检索匹配 question → 筛选候选 answer → (可选)answer 二次验证 → 生成。
具体步骤:
- 用户查询预处理:对用户输入的查询(如 “怎么重置手机”)进行分词(如拆分为 “怎么”“重置”“手机”)、去除停用词(如 “怎么”)。
- 全文检索匹配:
用处理后的查询词在 question 的全文索引中检索,通过关键词匹配度(如词频、逆文档频率 TF-IDF)排序,召回 Top N 个最相关的 question(如匹配到 “如何重置手机?”)。 - 提取候选 answer:获取召回 question 对应的 answer。
- (可选)answer 二次验证:
若存储了answer_embedding,可计算 “用户查询 embedding” 与 “answer_embedding” 的相似度,过滤无关答案(同前文逻辑);若未存储,可直接基于 answer 的全文检索进一步筛选。 - 生成:将筛选后的 answer 作为上下文输入 LLM,整理成自然语言。
案例:手机说明书 FAQ 的检索流程
场景:
存储的问答对:
qa_001: question="如何重置手机?", answer="步骤:1. 打开设置... 备份数据..."
qa_002: question="手机无法充电怎么办?", answer="检查充电器... 更换数据线..."
用户查询:“怎么重置我的手机?”
检索步骤:
- 查询预处理:
分词后得到关键词:“重置”“手机”(去除停用词 “怎么”“我的”)。 - 全文检索匹配:
引擎在 question 索引中检索含 “重置” 和 “手机” 的条目,qa_001的 question 完全匹配,得分最高(如 TF-IDF 得分 0.9),qa_002不匹配(得分 0)。 - 提取 answer:获取qa_001的 answer。
- (可选)二次验证:
若计算 “怎么重置我的手机?” 的 embedding 与answer_embedding的相似度为 0.85(高于阈值 0.6),确认有效。 - 生成:直接用 answer 整理为 “重置手机的步骤是:1. 打开设置... 请注意备份数据。”
优缺点与适用场景
优点:
- 低成本:无需为 question 生成 embedding,节省计算资源(尤其对大规模问答对)。
- 高精度:对关键词明确的场景(如技术术语、固定表述),匹配准确率高于向量检索(向量可能因语义泛化导致误匹配)。
- 可解释性:匹配结果基于明确的关键词,便于追溯为什么某 question 被召回。
缺点:
- 语义理解弱:无法处理 “同义不同词” 的查询,例如用户问 “如何恢复出厂设置?”,若 question 中只有 “重置” 而无同义词扩展,可能漏检。
- 依赖分词与索引质量:中文需高质量分词器(否则 “重置手机” 可能被拆错),且需维护同义词表(如 “重启”≠“重置”)。
适用场景:
- 结构化 FAQ(如客服话术、产品手册问答),question 表述固定。
- 关键词明确的领域(如法律条文、医疗术语问答)。
- 对成本敏感、无需处理复杂语义变体的场景。
优化建议
为弥补语义理解不足,可结合以下技巧:
- 同义词扩展:在索引中配置同义词表(如 “重置”→“恢复出厂设置”“初始化”)。
- 模糊匹配:允许关键词的部分匹配(如 “重值”→“重置”,通过编辑距离实现)。
- 混合检索:先通过全文检索召回候选 question,再用向量检索对候选结果做语义重排序(平衡精度与泛化能力)。
这种方案通过 “全文检索过滤 question”,在特定场景下能以更低成本实现高效检索,是向量检索的有效补充。
总结
问答对的拆分方式通过结构化存储(question, answer),在检索时实现了 “用户查询 - question-answer” 的精准映射,减少了无关信息干扰,尤其适合 FAQ、客服话术等场景;而普通文本块更通用,能处理无明确问答结构的文档,但检索效率和精准度可能稍低。在实际应用中,RAG 系统常结合两种方式(如对非问答文档用普通拆分,对 FAQ 用问答对拆分),以平衡覆盖范围和检索质量。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏
