"妙笔生维:线稿驱动的三维场景视频自由编辑" 这个标题听起来像是一个创新的技术或软件工具的名称,它可能结合了计算机图形学、计算机视觉和视频编辑等多个领域的知识。以下是对这个标题的详细解读:
1. "妙笔生维":这个部分可能寓意着通过简单的线条或草图(妙笔)就能创造出三维(生维)的场景或世界。它暗示了该工具的易用性和创造性,使得用户即使没有深厚的3D建模背景也能轻松创作出复杂的三维场景。
2. "线稿驱动":这表明该工具的核心功能可能涉及将二维的线稿或草图作为输入,然后基于这些线稿生成三维场景。这种方法可能比传统的三维建模技术更加直观和高效,特别是在快速原型设计和概念可视化方面。
3. "三维场景":这表明该工具专注于创建和编辑三维环境,可能包括建筑、室内设计、游戏场景、科学可视化等应用领域。
4. "视频自由编辑":这表明该工具不仅能够创建静态的三维场景,还能够将这些场景转换为动态的视频,并允许用户对视频进行自由编辑。这可能包括添加动画、调整相机视角、应用特效等操作。
综上所述,"妙笔生维:线稿驱动的三维场景视频自由编辑" 可能描述了一个强大的创意工具,它通过将线稿作为输入,让用户能够轻松地创建和编辑三维场景
相关内容:

刘锋林,中科院计算所泛在计算系统研究中心博士研究生(导师:高林研究员),研究方向为计算机图形学与生成式人工智能,在ACM SIGGRAPHTOG,IEEE TPAMI,IEEE TVCG,IEEE CVPR等期刊会议上发表论文10余篇,其中5篇为第一作者发表于SIGGRAPH和CVPR,4篇论文收录于中科院一区期刊ACM Transaction on Graphics,第一作者研究工作连续两年入选SIGGRAPH亮点工作宣传片(Video Trailer)。曾获得国家奖学金、中国计算机学会CAD&CG凌迪图形学奖学金等荣誉。
随着移动摄影设备的普及,基于手机或相机等可以快速获取带有丰富视角变换的三维场景视频。如何高效、自由地编辑这些三维内容成为一个关键挑战。例如,在视频中无缝添加新物体、精准去除不需要的元素,或者自然替换已有部分,这些能力在虚拟现实 (VR)、增强现实 (AR) 以及短视频创作中具有广泛的应用前景。
然而,现有的经典方法,通常只能添加预定义的三维模型库中的物体,极大地限制了用户的个性化创意表达。更关键的是,让新加入的物体融入原有场景的光影环境,生成逼真的阴影,以达到照片级的真实感,是具有挑战性的难题。同样,移除物体后,如何合理地填补空缺区域并生成视觉连贯合理的内容,也需要更优的解决方案。
近期,研究人员提出了一种基于线稿的三维场景视频编辑方法 Sketch3DVE ,相关技术论文发表于 SIGGRAPH 2025,并入选 Video Trailer。它赋予用户基于简单线稿即可重塑三维场景视频的能力。无论是为视频场景个性化地添加全新物体,还是精细地移除或替换已有对象,用户都能通过绘制关键线稿轻松实现。

- 论文标题:Sketch3DVE: Sketch-based 3D-Aware Scene Video Editing
- 论文地址:https://dl.acm.org/doi/10.1145/3721238.3730623
- 项目主页:http://geometrylearning.com/Sketch3DVE/
- Github:https://github.com/IGLICT/Sketch3DVE
此外,即使是单张静态图片,用户也能自由规划虚拟相机路径(指定相机轨迹),首先生成具有视角变化的动态视频,随后再进行任意编辑。
现在,就让我们一同探索 Sketch3DVE 如何将简单的线稿笔画,转化为重塑三维世界的钥匙!
视频加载中...
图 1 基于线稿的三维场景视频编辑结果
视频加载中...
图 2 视角可控的视频生成及编辑结果Part 1 背景
近年来,视频生成基础模型(如 Sora、Kling、Hunyuan Video、CogVideoX 和 Wan 2.1 等)在文本到视频和图像到视频生成方面取得了显著进展。精确控制生成视频中的相机轨迹因其重要的应用前景而受到广泛关注。
现有方法主要分为两类:一类工作 直接将相机参数作为模型输入,利用注意力机制或 ControlNet 结构来实现对生成视频视角的控制;另一类工作 则从单张输入图像构建显式的三维表示(如 NeRF),通过指定相机轨迹渲染出新视角图像,并以此作为控制信号引导视频生成。
尽管这些方法能够生成视角可控的视频,如何对已存在的、包含大幅度相机运动的真实视频进行精确编辑,仍然是一个有待解决的研究问题。
视频编辑任务与视频生成有本质区别,它需要保持原始视频的运动模式与局部特征,同时根据用户指令合成新的内容。早期的视频编辑方法 通常基于 Stable Diffusion 等图像扩散模型,对视频帧进行逐帧处理,并通过引入时序一致性约束来生成编辑结果。
进一步地,研究者开始利用视频生成模型进行编辑,例如一些方法 从输入视频中提取注意力特征图以编码运动信息,另一些方法 则采用 LoRA 对预训练视频模型进行微调以捕捉特定视频的运动模式。然而,这些方法主要擅长外观层面的编辑(如风格化、纹理修改),在几何结构层面的编辑效果较差,并且难以有效处理包含大幅度相机运动的场景。
线稿(Sketch)作为一种直观的用户交互方式,已被广泛应用于图像、视频和三维内容的生成与编辑中。基于线稿的视频编辑方法也已出现,例如 VIRES 通过优化 ControlNet 结构实现了基于线稿引导的视频重绘,而 SketchVideo 则设计了一种关键帧线稿传播机制,允许用户仅提供少量帧(1-2 帧)的线稿即可编辑整个视频。
尽管如此,现有的基于线稿的视频编辑方法主要面向通用场景。如何处理包含显著相机视角变化的视频,并在编辑过程中保持新内容的三维几何一致性,仍是当前研究面临的关键挑战。
Part 2 算法原理
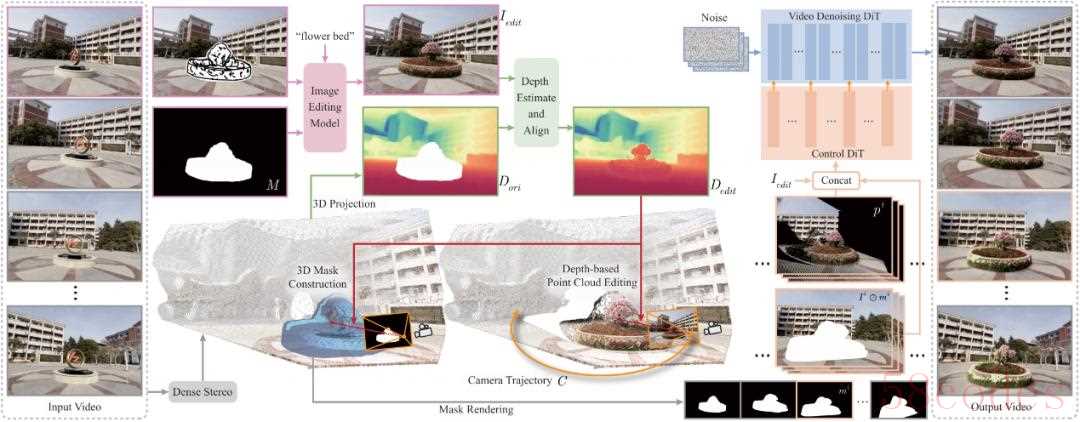 图 3 Sketch3DVE 的编辑流程和网络架构图
图 3 Sketch3DVE 的编辑流程和网络架构图给定输入的三维场景视频后,用户首先选定第一帧图像。在该帧上,用户绘制一个掩码(Mask)标记需要编辑的区域,并绘制线稿(Sketch)来指定新物体的几何形状。
同时,用户输入文本描述来定义新物体的外观特征。系统采用 MagicQuill 图像编辑算法(或其他兼容的基于图像补全的编辑方法)处理第一帧,生成该帧的编辑结果。
随后,系统利用 DUSt3R 三维重建算法处理整个输入视频,对场景进行三维分析。该方法输出第一帧对应的场景点云(Point Cloud)以及每一帧对应的相机参数(Camera Parameters),为后续的视频编辑传播提供几何基础。
接下来,需要将第一帧图像上的编辑操作传播到其对应的三维点云上。系统采用基于深度图的点云编辑方法:首先,使用 DUSt3R 或 DepthAnything 等方法预测编辑后第一帧图像的深度图(Depth Map)。由于预测得到的是相对深度值,需要将其与原始场景的尺度对齐。
为此,系统利用掩码外部(非编辑区域)的像素,通过逐像素的对应关系计算深度值的平移和缩放参数。应用这些参数对预测深度图进行变换,并将编辑区域的深度值融合到原始场景的深度图中。最后,通过反投影(Back-projection)处理融合后的深度图,得到编辑后的三维点云。
为了减少用户交互,掩码只需在第一帧绘制。为了将第一帧的掩码精确传播到后续不同视角的帧上,系统设计了一个基于三维感知的掩码传播算法。
该算法在三维空间中构建一个网格模型来表示三维掩码(3D Mask):利用编辑前后帧提供的深度信息和相机参数,将每个像素位置反投影到三维空间,形成网格顶点;根据像素邻域关系连接这些顶点,构建出表示编辑区域前表面的网格面片;后表面则使用平面结构并通过侧面连接,最终形成一个封闭的三维网格模型。该三维掩码模型可根据不同帧的相机参数渲染出对应的二维掩码。
最后,系统构建了一个基于三维点云引导的视频生成模型,其思路类似于 。该模型在预训练的 CogVideoX 模型基础上,额外引入了一个条件控制网络。
该网络以三种信息作为输入引导视频生成:1) 编辑后的第一帧图像;2) 由编辑后点云渲染得到的多视角视频(提供三维几何一致性约束);3) 原始输入视频(但移除了掩码区域的内容,用于保持非编辑区域的时空一致性)。通过融合这些条件信息,模型最终输出具有精确三维一致性的场景编辑视频。
Part 3 效果展示
如图 4 所示,用户可以在首帧绘制线稿并标记编辑区域,该方法可以生成高质量的三维场景视频编辑结果,实现物体的添加、删除和替换等操作,所生成新的物体具有良好的三维一致性。
视频加载中...
图 4 基于线稿的三维场景视频编辑结果如图 5 所示,当视频中存在阴影和反射等较为复杂的情景时,由于该工作使用了真实视频作为数据集进行训练,也能在一定程度处理上述情况,并生成相对合理的视频编辑结果。
视频加载中...
图 5 阴影和反射等情况的场景编辑效果如图 6 所示,给定真实拍摄的三维场景视频后,用户可以标记指定编辑区域,并绘制颜色笔画指定新生成内容的外观。该工作可以生成较为真实自然的三维场景视频编辑结果。
视频加载中...
图 6 基于颜色笔画的三维场景视频编辑结果如图 7 所示,该工作也支持不以线稿作为输入,而直接使用图像补全方法对首帧进行编辑,相关编辑效果也可以合理应用至三维场景。
视频加载中...
图 7 基于图像补全方法的三维场景视频编辑结果
Part 4 结语
随着大模型和生成式人工智能的迅速发展,三维场景视频编辑问题也有了新的解决范式。传统的模型插入方法存在难以个性化定制、渲染结果不够真实、无法去除已有物体等问题。
Sketch3DVE 则提出了一种有效的解决方案,通过线稿定制化生成三维物体,合成高真实感的三维场景视频编辑效果,并支持基于单目图像的三维视频合成和二次编辑。
借助该方法,用户无需掌握复杂的专业三维处理和视频处理软件,也无需投入大量时间和精力,仅凭几笔简单的线稿勾勒,便可以将想象中的物体带到现实,构建出灵感和现实的桥梁。该项工作已经发表在SIGGRAPH 2025。
有关论文的更多细节,及论文、视频、代码的下载,请浏览项目主页。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏
