我们来聊聊AI看视频时“说胡话”的问题,以及Omni提出的“侦探式”三步法如何提升AI的可信度。
"为什么AI看视频会“说胡话”?"
AI(尤其是大型语言模型)在理解和生成关于视频内容的信息时,确实会遇到挑战,导致输出不准确或“胡话”。主要原因包括:
1. "视觉信息理解局限:" 虽然AI在图像识别方面进步巨大,但完全理解视频的复杂视觉场景(如细微表情、眼神交流、复杂动作、场景隐喻)仍然困难。它可能只“看到”孤立的物体或动作,而忽略了上下文和深层含义。
2. "多模态信息融合困难:" 视频包含视觉、听觉(语音、音乐、环境音)等多种信息流。AI需要将这些信息有效融合,但不同模态的信息可能存在冲突或不一致,AI难以判断哪个是“真相”,容易产生矛盾或错误的解读。
3. "上下文理解不足:" 视频是连续的、动态的。理解一个片段需要结合前后内容。AI可能缺乏足够的“记忆”或推理能力来准确把握长时上下文,导致基于局部信息做出错误推断。
4. "事实核查能力欠缺:" AI主要依赖训练数据。如果数据中存在错误信息,或者AI在推理时跳过了关键事实核查步骤,就可能出现“
相关内容:
自动驾驶、智能监控、电商视频等业务中,AI 视频理解常出错,导致运营成本高、法律纠纷多。Omni 体系带来新突破,其“侦探逻辑”能解决细节与信任等核心痛点,还有三大商业化场景应用,让 AI 视频理解走向可信。

自动驾驶、智能监控、电商视频等业务中,AI 视频理解常出错,导致运营成本高、法律纠纷多。Omni 体系带来新突破,其“侦探逻辑”能解决细节与信任等核心痛点,还有三大商业化场景应用,让 AI 视频理解走向可信。
如果你是负责自动驾驶、智能监控或者电商视频业务的产品经理,肯定遇见过这种糟心事儿:AI把“穿蓝衣服的小孩”硬说成“绿的”;行车记录仪里明明没划痕,AI定损报告却写着“多处漆面损伤”。这可不是小bug——往小了说,运营得花半天擦屁股;往大了说,直接触发法律纠纷、高额赔付,老板的脸色能阴一整天。
现在多模态AI炒得火热,但视频理解这块始终是块“硬骨头”,逃不开两难:要么细节糙得像马赛克,只能识别“有人有车”,对业务没用;要么细节一丰富就开始“满嘴跑火车”,幻觉率蹭蹭涨。咱们做PM的,谁关心模型参数量多大?要的是能直接部署、出了问题能溯源、还能帮公司省钱的实在方案。
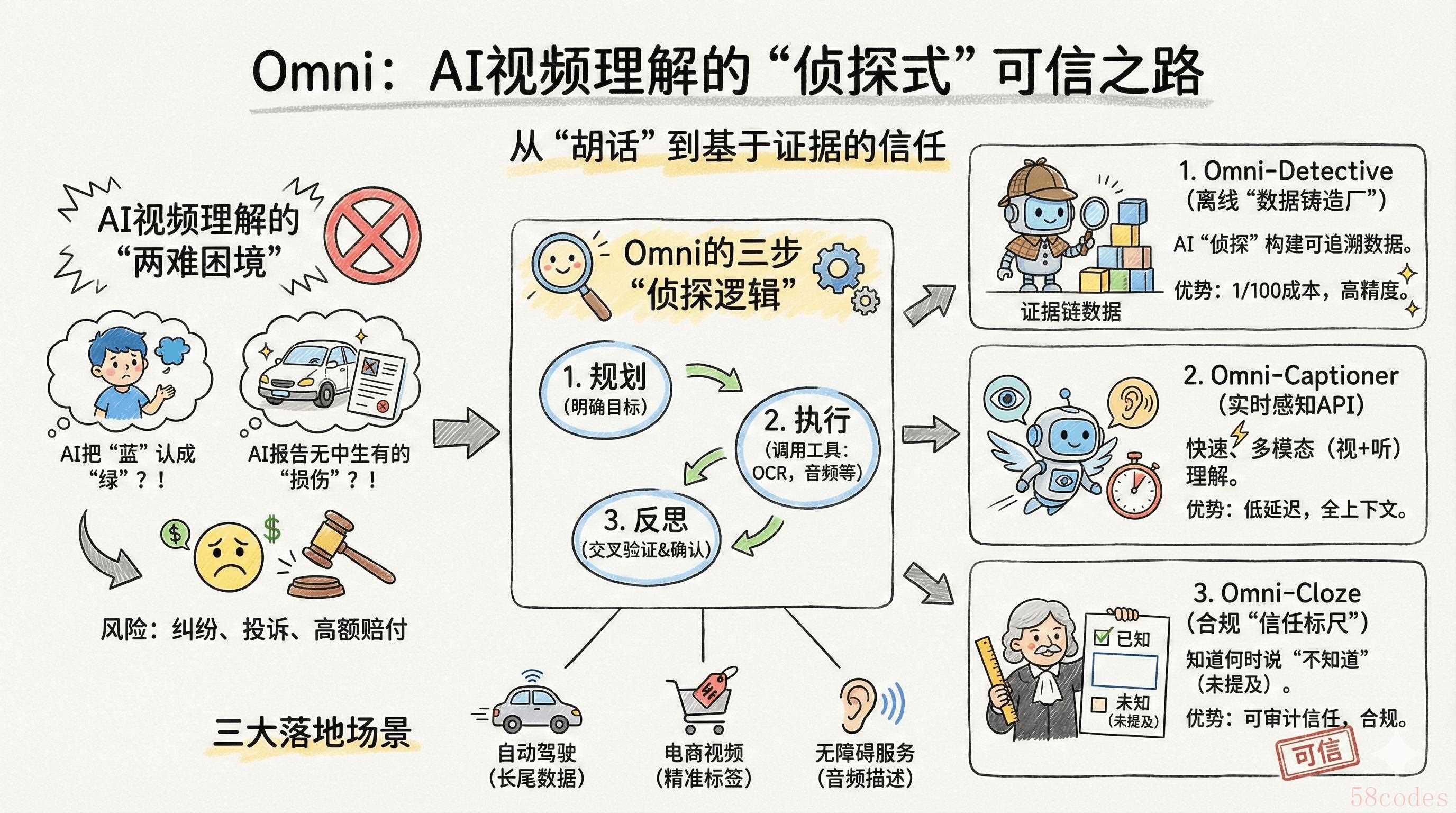
最近我沉下心啃了Omni-Captioner和Omni-Detective的论文,越看越兴奋——这玩意儿不是堆理论,是把“侦探查案”的思路做成了可落地的三模块体系。能把人工标注成本砍到地板价,把幻觉从“定时炸弹”变成“可追溯的证据链”,连合规需要的信任度量都给准备好了。今天我就把论文里的技术逻辑,拆成咱们PM能直接用的落地路径,全是干货,直指成本、可信、合规这三个核心痛点。
核心痛点:视频理解的“两难困境”,企业不敢用的根源
先掰扯个真相:企业要的从来不是“能看视频的AI”,是“看了之后敢信、能当依据的解读”。但现在的技术就卡在这里,三个坎儿绕都绕不开,也是我做方案时优先要拍死的问题。
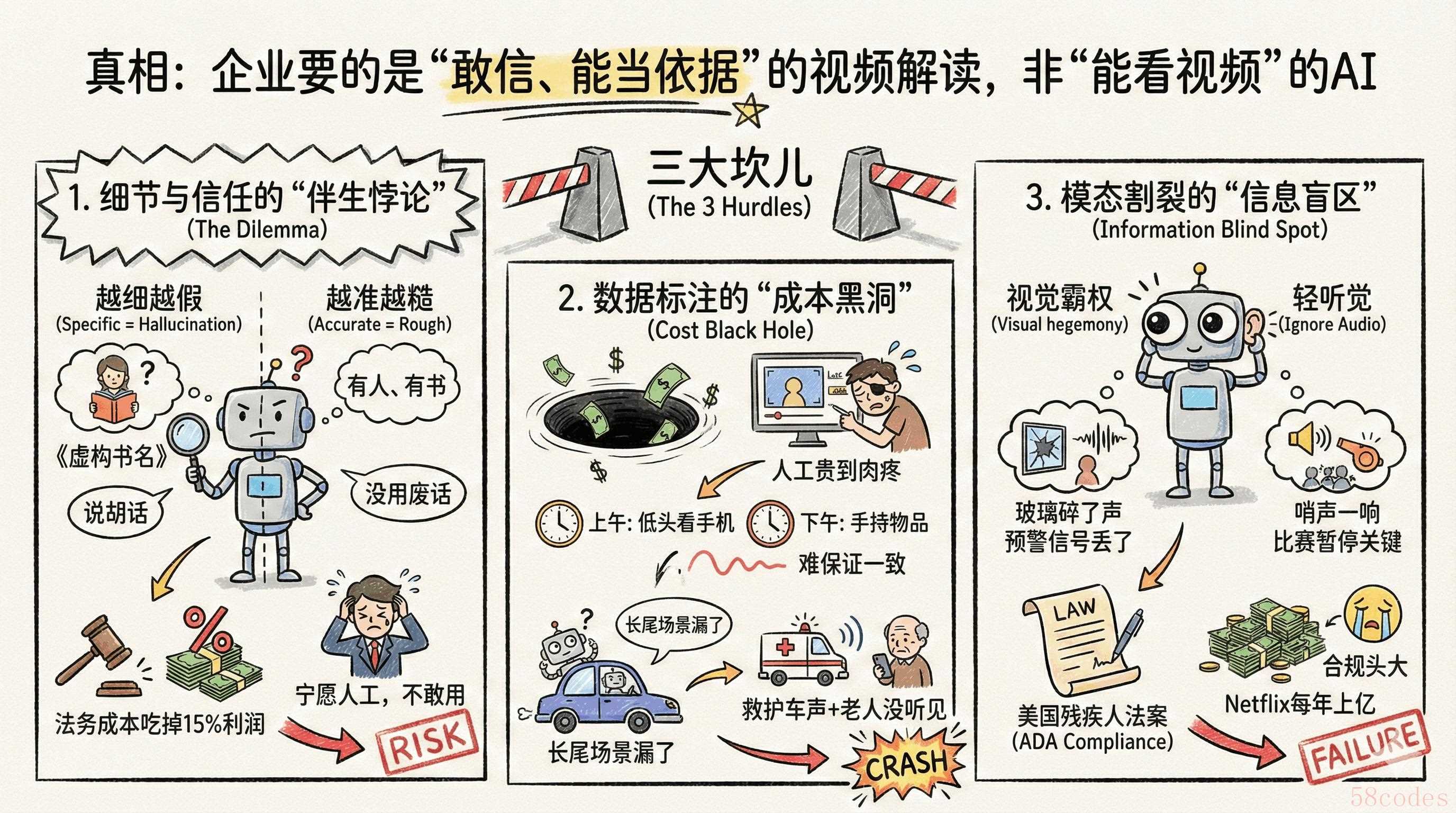
1. 细节与信任的“伴生悖论”:越细越假,越准越糙
传统视频AI的路子特别简单粗暴,就是“扫一眼就下结论”。比如分析监控,看到人拿本书就敢编书名,听到点噪音就猜是“施工”。客户要细节,就得捏着鼻子忍它“说胡话”;要准,就只能拿到“有人、有书、有噪音”这种没用的废话——典型的“要么没用,要么添乱”。
我跟保险行业的朋友聊过,他给我算过一笔账:AI定损报告哪怕只有5%的幻觉率,一万份理赔单里就有500份要扯皮,光法务诉讼费就能吃掉15%的利润。所以现在很多公司宁愿花大价钱请人工标注,也不敢用看似高效的AI——毕竟“慢但准”比“快但错”安全多了。
2. 数据标注的“成本黑洞”:人工贵到肉疼,还难保证一致
AI是喂出来的,好数据就是好饲料,但视频标注这活儿是真的“又苦又贵”。密集标注要求人每秒盯着画面记细节,几小时下来眼都花了,更坑的是,人不是机器,状态一差就出错——上午标“低头看手机”,下午可能就写成“手持物品”,前后不一致,模型学了也白学。
有个做自动驾驶的客户跟我吐过槽,他们每年砸在长尾场景标注上的钱就几千万,但还是漏了好多关键场景,比如“救护车声里,老人低头看手机没听见”——这种关联信息一丢,模型在极端情况就容易“宕机”,出事儿就是大问题。
3. 模态割裂的“信息盲区”:重视觉轻听觉,丢了半条命
现在90%的视频AI都是“视觉霸权”,把音频当摆设。但真到业务里,声音往往是“预警信号”:安防里“玻璃碎了但画面没人”,比“画面有裂纹”早预警十分钟;体育赛事里“哨声一响球员停步”,才是判断比赛暂停的关键——光看画面,根本抓不住。
流媒体平台的合规负责人更头大,《美国残疾人法案》逼着视频必须配音频描述,得把环境音、动作细节全说清楚。但现有AI只认画面,声音信息全丢,最后还是得靠人工写脚本,Netflix每年花在这上面的钱都上亿,中小平台根本扛不住。
破局关键:Omni体系的“侦探逻辑”,把信任钉死在细节里
啃完论文我才发现,Omni体系牛在哪儿?不是参数堆得高,是把视频理解的逻辑彻底改了——从“猜结论”变成“查证据”。这就像咱们做用户调研,不会只听一个用户的反馈就定方案,肯定要交叉验证、反复确认。论文里这套“先规划、再执行、最后反思”的闭环逻辑,简直就是为产品落地量身定做的——这也是我把它改成实际方案的核心思路。落实下来,就是三个环环相扣的模块,全是从论文里扒出来的干货。
1. Omni-Detective:离线“数据铸造厂”,把人工成本砍到1/100
这个模块就是论文里的“代理式数据生成管线”,我直接把它定位成“AI标注组长”,专门干离线的、高精度的脏活累活。论文的逻辑特别好懂:让AI学侦探办案,先明确要查啥,再叫工具来帮忙,最后把证据拼起来——我设计产品流程的时候,几乎没改这个逻辑,太实用了。
比如处理自动驾驶路测视频,它不直接瞎咧咧,而是按三步来:第一步“定方向”,明确要找“异常行人+相关声音”;第二步“查细节”,看到行人就调姿态模型确认“是不是低头”,听到声音就用音频工具定位“是救护车,在左后方”;第三步“核证据”,看看“行人低头”和“救护车声”是不是同时发生,避免瞎编。
对咱们PM来说,这价值太实在了:一是砍成本,自动化标注把时薪从几百块压到几毛钱,精度还比人高;二是能溯源,每个细节都带着“出身证明”,比如“车牌XYZ(OCR扫的,可信度98%)”,出了问题一查就准,黑盒模型根本做不到这一点。
2. Omni-Captioner:在线“实时感知API”,低延迟接高频需求
论文里明说,Omni-Captioner是Omni-Detective的“蒸馏学生”——意思就是把老师傅的手艺浓缩教给徒弟,本事没丢,还更灵活高效。这个定位太关键了,我直接把它做成在线服务,专门接实时需求。论文里的两阶段训练法(先单练音频,再音视频一起练)是核心卖点,天生就解决了“重画面轻声音”的破毛病,这就是咱们的差异化竞争力。
我做产品时重点强化了两点:一是“全感官懂行”,先让模型闭着眼练音频,把“听声辨位”练熟,再结合画面,能直接解读“听到争吵+看到脸红=情绪激动”这种关联信息;二是“轻量能落地”,参数量控制在7B到13B,边缘端的GPU就能跑,延迟压到200毫秒以内,实时监控、直播审核都能扛住。
有个做智能监控的客户试过之后反馈特别好:以前的AI只会喊“有人闯入”,现在能直接说“穿工装的男的,拿着手工具,还有金属敲击声,像是在施工”,安保响应快了3倍,不用再派人瞎跑了。
3. Omni-Cloze:合规“信任标尺”,让AI学会“不知道就说不知道”
做To B产品,合规是红线,躲都躲不开。但怎么证明AI“靠谱”?论文里的Omni-Cloze评测框架正好解决了这个问题。它搞了个创新,用“完形填空+‘没提过’选项”,逼着模型分清“不知道”和“我知道”——这个逻辑太妙了,我直接把它做成“合规审计工具”,完美踩中欧盟AI法案的要求。
这东西的价值在哪儿?就是让AI别瞎自信。比如视频里红绿灯拍糊了,模型必须说“没检测到”,不能瞎猜“绿灯”——这在自动驾驶、金融场景里,可是救命的。我们把它包装成“合规报告”服务,客户把AI输出传上来,立马能拿到GDPR或者AI法案的评分,金融、医疗这些强监管行业的客户特别吃这一套。
落地路径:三大商业化场景,从“能用”到“好用”
技术说得再天花乱坠,落不了地都是白搭。我啃完论文,结合手里的客户痛点,把Omni体系拆成了三个能直接上手的场景,每个方案都是把论文里的技术逻辑,改成了业务能直接用的打法。
1. 自动驾驶:挖透“长尾场景”,解决数据短缺难题
自动驾驶的命门就是“长尾场景”——比如“树荫下穿绿衣服的小孩突然冲出来”“救护车响着笛,行人还横穿马路”,这些场景少见但致命,人工标注根本挖不全,等于给模型留了安全隐患。
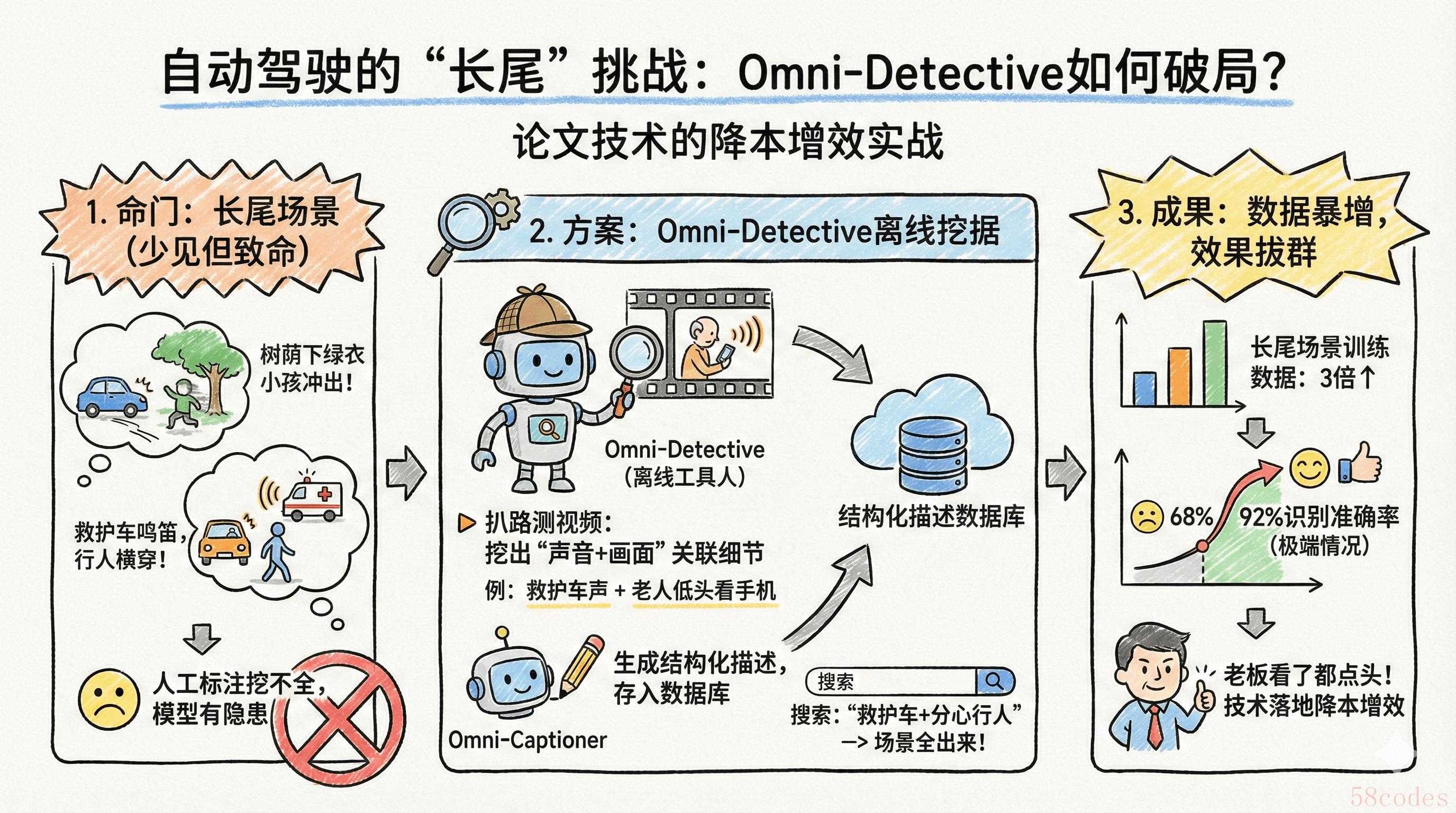
我的方案就照着论文来:让Omni-Detective这个“离线工具人”先去扒路测视频,把“声音+画面”的关联细节都挖出来,比如“救护车声+老人低头看手机”;再让Omni-Captioner把这些信息写成结构化描述,存到数据库里。数据科学家不用再一帧帧看视频,直接搜“救护车+分心行人”,想要的场景就全出来了——这就是论文技术最实在的降本增效。
有个新势力车企试了之后,长尾场景的训练数据直接多了3倍,模型在极端情况的识别准确率从68%涨到92%——技术落地的效果,老板看了都点头。
2. 电商视频:精准打标签,让UGC视频“活”起来
电商平台的UGC视频是座金矿,但标签不准就成了废矿。比如美妆博主的试色视频,以前只能标“口红、试色”,用户搜“滋润型口红,博主涂完笑了”根本搜不到——流量就这么浪费了,运营能不急吗?
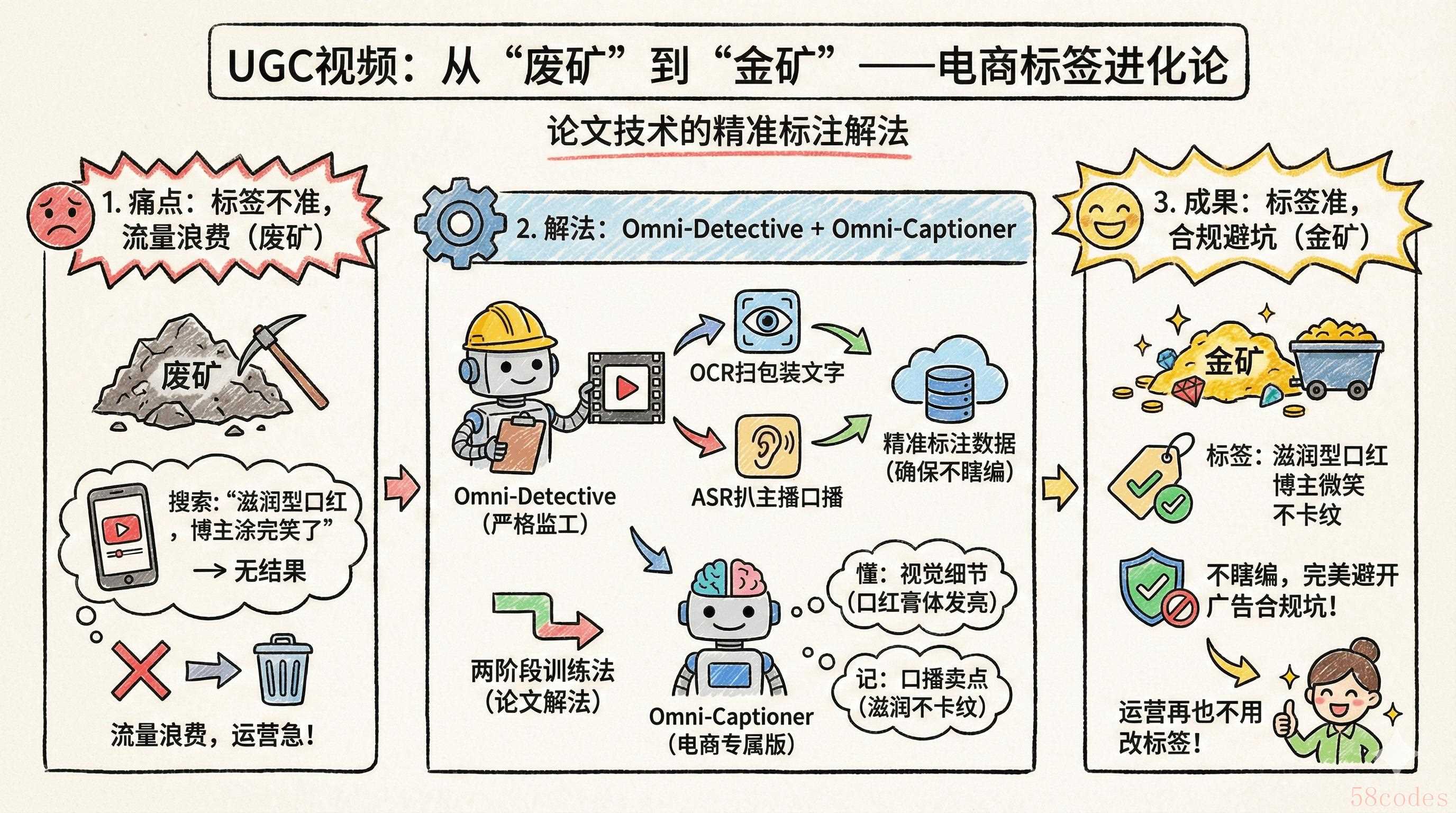
我的解法也是从论文里扒的:先让Omni-Detective这个“严格监工”去做电商视频的标注数据,强制它用OCR扫包装文字、用ASR扒主播口播,确保商品信息没瞎编;再用论文里的两阶段训练法,把Omni-Captioner调成“电商专属版”。这样训出来的模型,既懂“口红膏体发亮”这种视觉细节,又记得“滋润不卡纹”这种口播卖点,标签准得很。
最关键的是它不瞎编——包装上没写“成分天然”,绝对不会乱加,完美避开广告合规的坑,运营再也不用天天改标签了。
3. 无障碍服务:自动做音频描述,帮平台省80%合规成本
《美国残疾人法案》卡得特别严,流媒体平台的视频必须配音频描述,得把环境音、动作细节全说明白。Netflix每年花在这上面的钱都上亿,中小平台根本扛不住,合规负责人头发都愁白了。
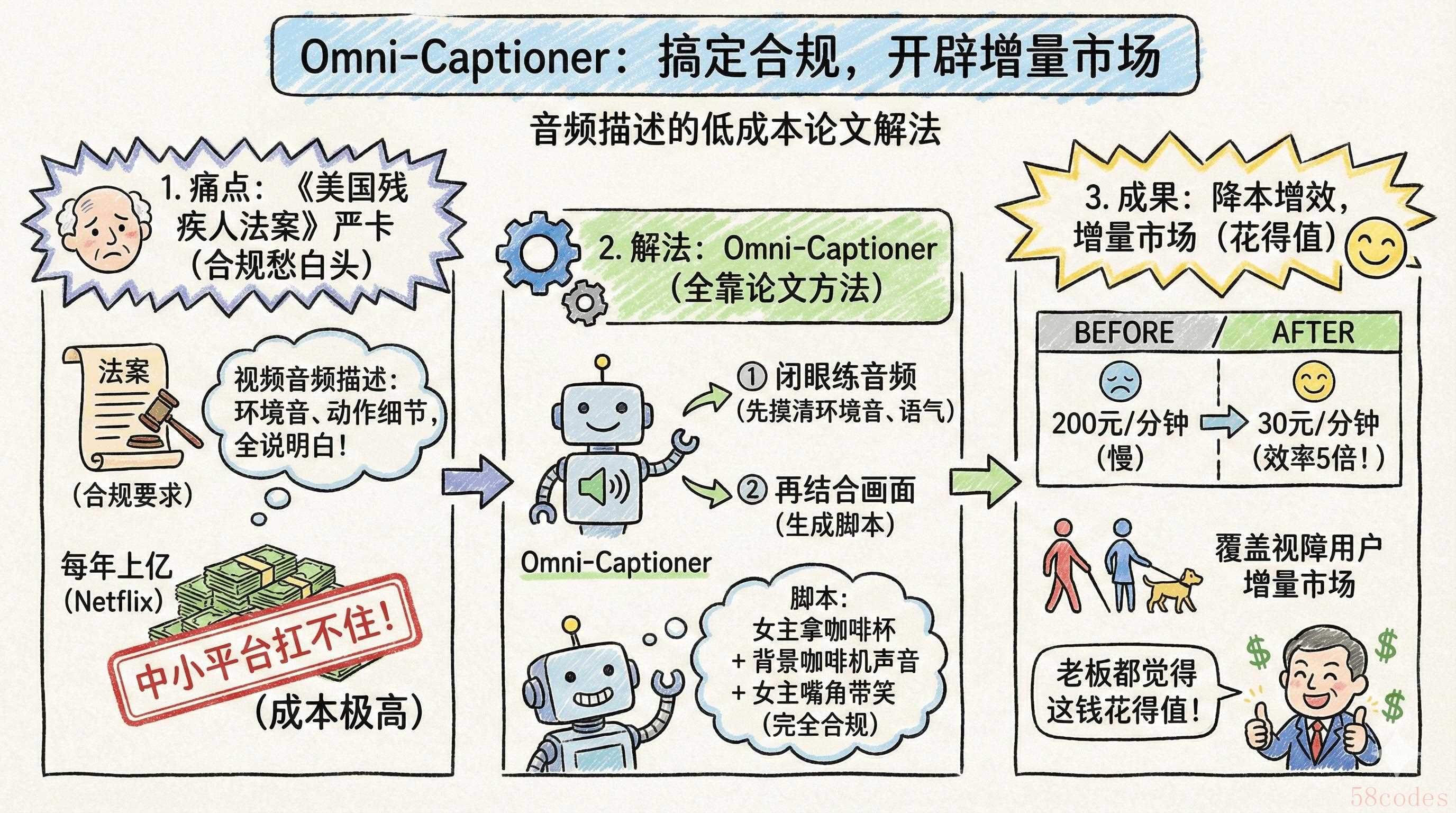
Omni-Captioner能搞定这个,全靠论文里的训练方法——先让它闭着眼练音频,把环境音、语气这些细节摸得门儿清,再结合画面。它生成的音频脚本,不光说“女主拿咖啡杯”,还会补“背景有咖啡机的声音,女主嘴角带着笑”,完全符合合规要求。
有个短视频平台试了之后,音频描述的成本从200元/分钟降到30元,合规效率快了5倍。对平台来说,这哪儿是成本项?是能覆盖视障用户的增量市场,老板都觉得这钱花得值。
结语:AI视频理解的下一站,是“可信”
做PM久了就明白,好的技术转化不是炫技,是解决真问题。啃Omni论文的时候,我最受触动的就是它“证据优先”的逻辑——正好戳中了视频AI“不可信”的死穴。咱们的活儿,就是把论文里的技术框架,改成企业能直接用、敢放心用的方案。
本文由 @命运石之门 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏
