CTS 是甚么 ?
全名为 clock tree synthesis,旨在将外部 clock 妥善分配给内部的各个元件。由于 CTS 需要精确各元件的位置以计算準确的延迟与可运行频率,且 clock routing 是主要 power 耗损的主要来源 (30%附近) ,须优先于 signal routing,因此一般 CTS 在 place 之后 route 之前进行。
CTS 的目的是甚么 ?
CTS 是一个 clock balancing 的技术,旨在维持讯号的完整性。常见 clock 的参数有 clock uncertainty, clock skew, clock transition 和 clock latency 等。其中最主要的目的是降低 clock skew 和 clock latency。内容主要参照这里。
1. clock uncertainty

上图为 clock jitter,可见各週期的长度有些微差距。多为 clock source 或锁向迴路不稳定造成的现象,导致线路上某点的 clock 週期不固定,因此并非 CTS 主要要优化的地方。CTS 在这部分的主要工作是给定 jitter 造成的 uncertainty 并用以保留 timing margin。在 pre-CTS 中的 setup / hold uncertainty 使用使用者设定的 uncertainty (jitter) 与 clock skew 来评估 margin,在 post-CTS 则只参照较为精确的 jitter 值。
2. clock skew
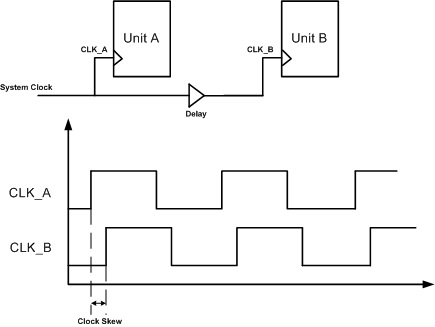
上图即为 clock skew 之示意图。由于从 clock root 到 leaves 的长度并不全然相同,因此便造成了 latency 落差,其定义为最长的 latency 减去最短的 latency,在评估时多用 +- 5~10%估计。clock skew 是 CTS 主力要优化的目标,也是衡量一个 clock tree 好坏的指标。
根据 clock 和 data propagate 的方向相同或相异,可以分为 positive 和 negative skew,其中 positive skew 可以想成给定时钟频率,讯号在传输时感觉到的週期却上升了。引公式后可以发现positive skew 时 T 的下限减少且 hold time 的上限下降,如此便导致 performance 增加但 hold time 更难以符合,而 negative clock skew 则刚好相反。
而根据 clock skew 产生的 cell 之间的关係,又可以分为 global skew,local skew 和 interclock skew,而 CTS 主要要优化的是 global skew,也就是前述提到的最长的 latency 减去最短的 latency。 local skew 则较常使用于 STA 分析时,在考究 signal 在各个 cell 的 arrival time 与 require time 会使用到。而 interclock skew 则是计算不同 clock 之间的 latency 差异,视设计需求看是否需要在 CTS 进行 balance。
虽然 CTS 的主要目标是尽量减少 skew,但如同前面提到的 positive skew 和 negative skew 的特性,藉由 useful skew 的技巧可以用来解决 timing violation,其中前者可以用以符合 setup time requirement 而后者则对 hold time requirement 有利。
3. clock latency
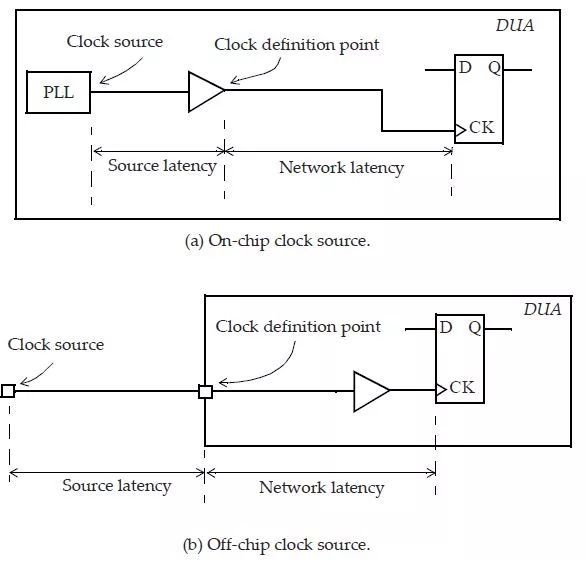
上图为 clock latency 的示意图,依照 latency 来源可以分为 source (off-chip) latency 和 network (on-chip) latency,而 CTS 主要是改良后者。
在进行 CTS 时,我们会自行定义我们预期中的总体 clock latency,而 eda 工具则是藉由插入 buffer 的方式来尽量符合要求。latency 也是会直接影响 skew 结果的要素,由于 time derate 的因子以比例计算,因此太长的 latency 势必让后续平衡 clock skew 时更难处理。关于 time derate 与 latency 的关係在稍等 clock tree 的实践那一节介绍。
4. clock transition
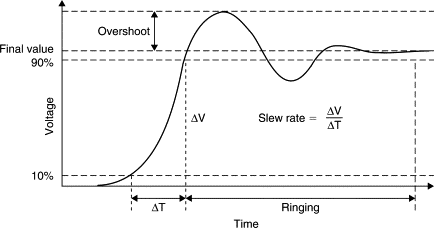
上图的 便是 clock transition time,定义为 rising edge 中从 10% VDD 升到 90% VDD 和 falling edge 时从 90% VDD 降到 10% VDD 的平均值。与 latency 相同,我们可以藉由指令让 transition 尽量符合预期值。过长的 transition 会造成 timing 问题,而过短的 transition 则会因插入过多 buffer 影响其他 clock balance,congestion 等问题。
CTS 的输入输出
CTS 的输入有细部摆置 (DEF 档)、clock tree 的实践方式 (架构与使用 IV/BUF)、on cip 与 off chip 的各项延迟目标 (SDC 档)、clock tree constraint。输出包含加入 CTS 后的摆置、 SPEF 档与 CTS 后的 netlist。Clock Tree 的架构实现
CTS 在一般情况下,希望级数达到最少,但同时各个 trunk 都不希望有过多的 fan-out。Cadence 的 clock tree 架构主要有分为以下几种:H-tree、Mesh 和最近推出的 Flexible H-tree。

如上图, H-tree 是一种碎形结构,特色是同一级的结构末端到 clock root 的路径长都一样,也同时意味着该结构天然能使得 leaves 的延迟保持完全一样,且覆盖範围可及平面任一点。而较新推出的 Flexible H-tree 能更方便的让使用者设定 H-tree,如定义每个 H-tree 的长宽与不需做 H-tree 的区域等,详细可见这里。缺点则是因灵活性较低,水平与垂直布线因需控制延迟而依定须存于相邻的 metal layer,因此对于低功耗的设计效果不佳。类似的架构有 X-tree,Y-tree。
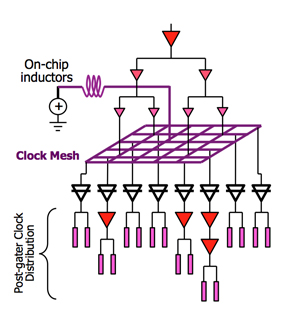
Mesh 结构是一种立体的网格分布,先通过多级 buffer 到达网格结构,并利用其特性使接到的 FF 有相近的延迟。细部架构参照这里。
随着製程越做越微小,製成的 variation 影响也越来越大 (包含刻蚀、不同点温度差异、crosstalk 等),而这样的差异也导致 clock skew 的变异因此提升,IC 设计师过去以提升电路在时间上的容错率来避免各种 timing violation。该方式称为时序增减 (Time derating),目前製成大部分会将时序增减因子设为 5~10%。补充一下 variation的部分,除了常见的 OCV (Local on-chip variation),还有 Global chip-to-chip variations,前者存在 Die 内而后者则存在在 Die 之间。
然而相对 clock tree 来说,clock mesh 是一个天生对 OCV (on-chip variation) 具有很强容错率 (tolerance) 的架构。 由于 mesh 出现,使得 clock skew smoothing 效果良好,如下图
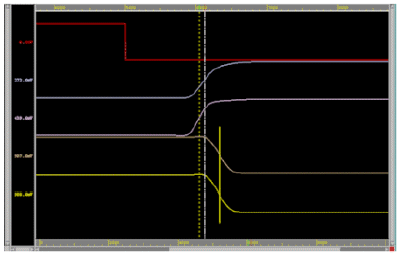
前两个讯号是进入 mesh net 前的 clock skew,而后者则是经过 mesh net 后在 leaves 观察到的波型。
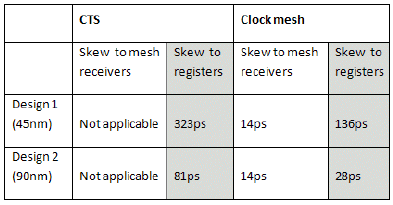
上图则是 clock tree 对 clock mesh 的比较图,可以发现刚出 mesh net 的 skew 都能压的非常低。最主要的原因是 clock mesh 对leaves有较大量的结构共用,因此在面对相同 non-OCV skew (例如原先就有 routing 长度差异) 与同等时序增减因子情况下造成实际的 OCV skew 有高达3倍或更多的差距。
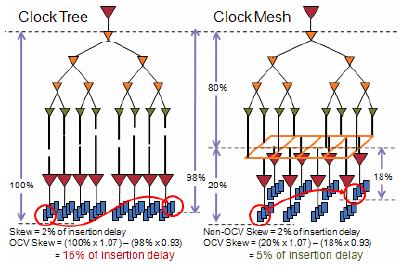
由上图可以感受到是否共用路径影响 clock skew 非常多,而当共用的比例提升时 clock skew 的数值也越来越小。另外需要注意的是 latency,也就是上图中的 insertion delay 与最终的 clock skew 。
CTS 的限制
由于 CTS 会增加 BUF/IV 来做 clock balancing,因此可能导致阻塞 (congestion) 和 crosstalk noise 、latency等。同时在过程中也会使得 non-clock cells 被移动到非预期的位置。
注: crosstalk 为串扰,两条signal之间电容性偶合会产生耦合电流,而电感性耦合会造成耦合电压。
结论
CTS 是相当重要的技术,除了会影响 PPA 外,也决定了一个晶片是否能成功运行。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏


