安装requests!!!
前因:
刚开始接触爬虫的时候,学到的是以selenium为主搭配为爬虫设置的geckodriver浏览器,模拟人类使用网页的方法,取得所需要的资料。selenium插件是一款非常直观的爬虫方式,利用selenium搭配网页的原始码,可以很轻易的做出跟人类操作一模一样的动作,但使用一段时间后发现,selenium方便归方便,但是这是因为它还是使用了浏览器的功能,它只是模拟人类使用浏览器的方式。造成它在爬资料的时候,速度其实不快,更由于使用浏览器的关係,它无法在纯终端机作业系统中进行操作,这对于在远端部署爬虫时是个致命的缺点。因此在朋友的强迫下,我开始接触requests这个套件。
requests的安装与使用:
安装requests跟安装python其他套件一样简单。
在安装完Python的环境中(我使用的是Python3.8),使用终端机安装。
pip install requestsor
pip3 install requests执行完便成功安装resqusts套件。
resqusts使用方法:
requests套件支援了HTTP的各种请求方法,其中GET与POST最常使用到,而我目前也只使用过这两个方法就能达成一般爬虫所需要的条件。以下示範如何使用requsts套件抓取网页。
一般而言造访一个网站,通常都以GET这个方法达成。而使用什么方法我们可以在网页上开启开发人员工具来得到网页的资讯。
以最常造访的google首页来做範例。
import requestsresult=requests.get("https://www.google.com/")只要使用requests.get这个方法就可以得到该网页的资讯:
print(result.status_code)print(result.text)print(result.content)我们可以由result.status_code拿到网页的状态码,200代表正常。
result.text则是解过码的字符串(比如html代码)。当requests发送请求到一个网页时,requests库会推测目标网页的编码,并对其解码,转为字符串(str)。这种方法比较容易出现乱码。
result.content是未解码的二进位格式(bytes),不仅支持文本内容,还适用于二进位文件内容如图片和音乐等。如果需要把文本内容转化为字符串,一般使用result.content.decode('utf-8')方法即可。
以下为requsts可使用的HTTP请求方式。
import requests requests.get("http://xxxx.com/")requests.post("http://xxxx.com/post", data = {'key':'value'})requests.put("http://xxxx.com/put", data = {'key':'value'})requests.delete("http://xxxx.com/delete") requests.head("http://xxxx.com/get")requests.options("http://xxxx.com/get")session
requests提供了一个session的功能,让网页不会重新读取,每次读取视为同一次。
可以用以下程式码实现。
session_requests = requests.session()result = session_requests.get("http://xxxx.com/")在requests网页的同时,我们可以附加上我们给定的headers值,如以下程式码,让我们在拜访网页的时候,可以伪装成一般浏览器与网页的交流。
headers = {'user-agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36","Accept-Language": "zh-TW,zh;q=0.9,en-US;q=0.8,en;q=0.7"}result = session_requests.get("http://xxxx.com/", headers=headers)headers以字典的方式存在于python的语言中。
提交资料
如果网页要求提供资料以POST的模式,我们可以查看开发者人员模式下,选择Network确认该网页要求POST。
开发者人员模式拉到最下方可以观察这个网页所需要的FOR表。
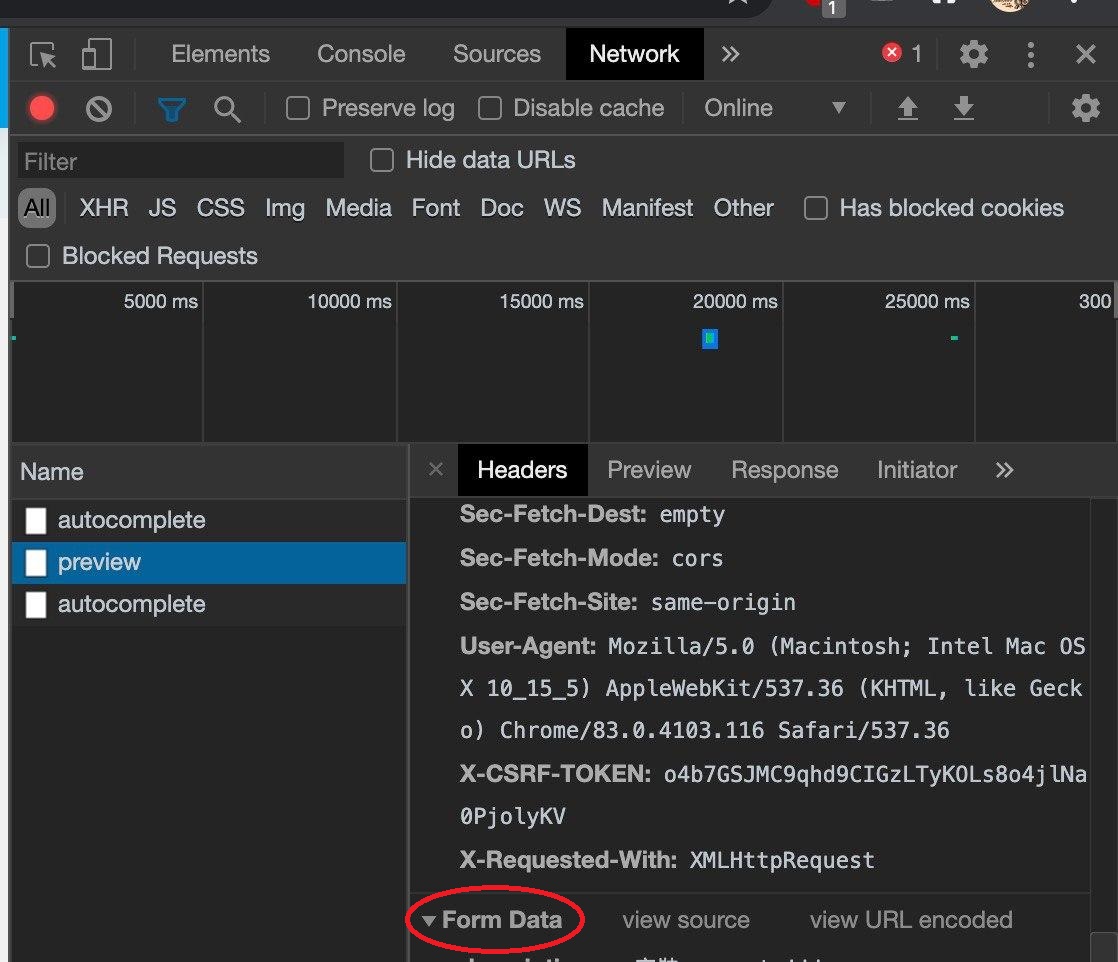
此时就可以根据FORM Data表看到所需要的资料,并以此做出以字典的方式做出要上传的Data。
data = { "xxxx": "xxxx", "yyyy": "yyyy",}此时便可使用request.post指令上传所需的资料。
result = requests.post("http://xxxx.com/", data=data, headers=headers)关于requests的部份暂时就介绍到这边,下篇文章会介绍如何分析我们用requests所抓取的网页。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏


